NLP이냐 텍스트 분석이냐?
NLP는 머신이 인간의 언어를 이해하고 해석하는 것,
테스트 분석은 비정형 텍스트에서 의미 있는 정보를 추출하는 것에 중점을 둔다.
NLP는 기계 번역, 질의 응답 시스템에서 사용되고, 텍스트 분석은 텍스트 분류, 감정 분석, 텍스트 요약, 텍스트 군집화 등을 실시한다.
이번 장에서는 텍스트 분석을 중심으로 진행한다.
01. 텍스트 분석 이해
텍스트를 머신러닝 알고리즘으로 학습하기 위해서는 word 기반의 다수의 피처로 추출하고 이 피처에 단어 빈도수와 같은 숫자 값을 부여하여 벡터값으로 표현한다.
이를 피처 벡터화 또는 피처 추출이라고 하며, 대표적으로 BOW(Bag of Words)와 Word2Vec 방법이 있다.
텍스트 분석 수행 프로세스
1. 텍스트 사전 준비작업(텍스트 전처리) : 텍스트 정규화 작업 수행. 대/소문자 변경, 특수문자 삭제, 토큰화 등
2. 피처 벡터화/추출 : 가공된 텍스트에서 피처를 추출하고 벡터값을 할당한다.
3. ML 모델 수립 및 학습/예측/평가 : 피처 벡터화된 데이터 세트에 ML 모델을 적용한다.
파이썬 기반의 NLP, 텍스트 분석 패키지
- NLTK : 대표적인 NLP 패키지. 방대한 데이터 세트와 서브 모듈을 가진다. 수행 속도가 느려 실제 업무에서는 활용되지 않는다.
- Gensim : 토픽 모델링 분야에서 가장 잘 활용된다.
- SpaCy : 뛰어난 성능으로 최근 가장 주목을 받는 패키지이다.
02. 텍스트 사전 준비 작업(텍스트 전처리) - 텍스트 정규화
텍스트 정규화 작업은 클렌징(Cleansing), 토큰화(Tokenixation), 필터링/스톱 워드 제거/철자 수정, Stemming, Lemmatization 등으로 분류할 수 있다.
클렌징
텍스트 분석에 방해가 되는 불필요한 문자, 기호 등을 사전에 제거하는 작업이다.
텍스트 토큰화
문서에서 문장을 분리하는 문장 토큰화와 문장에서 단어를 토큰으로 분리하는 단어 토큰화로 나뉜다.
문장 토큰화
문장의 마침표(.), 개행문자(\n) 등 문장의 마지막을 뜻하는 기호에 따라 분리한다.
NLTK에서 많이 쓰이는 sent_tokenize()를 통해 토큰화가 가능하다.
from nltk import sent_tokenize
import nltk
nltk.download('punkt')
text_sample = 'The Matrix is everywhere its all around us, here even in this room. \
You can see it out your window or on your television. \
You feel it when you go to work, or go to church or pay your taxes.'
sentences = sent_tokenize(text=text_sample)
print(type(sentences),len(sentences))
print(sentences)<class 'list'> 3
['The Matrix is everywhere its all around us, here even in this room.', 'You can see it out your window or on your television.', 'You feel it when you go to work, or go to church or pay your taxes.']nltk.download('punkt')는 마침표, 개행 문자 등의 데이터 세트를 다운로드한다.
list 객체로 반환된다.
단어 토큰화
기본적으로 공백, 콤마, 마침표 등으로 단어를 분리하지만, 정규 표현식을 이용해 다양한 유형으로 토큰화를 수행할 수 있다.
BOW와 같이 단어의 순서가 중요하지 않은 경우 단어 토큰화만 사용해도 충분하다. 일반적으로 문장 토큰화는 문장이 가지는 시맨틱적인 의미가 중요한 요소로 사용될 때 사용한다.
NLTK에서 제공하는 word_tokenize()를 이용해 단어로 토큰화를 진행한다.
from nltk import word_tokenize
sentence = "The Matrix is everywhere its all around us, here even in this room."
words = word_tokenize(sentence)
print(type(words), len(words))
print(words)<class 'list'> 15
['The', 'Matrix', 'is', 'everywhere', 'its', 'all', 'around', 'us', ',', 'here', 'even', 'in', 'this', 'room', '.']
문장을 단어별로 토큰화하는 경우 문맥적인 의미가 무시된다.
이러한 문제를 해결하기위해 n-gram이 도입되었다.
n-gram이란 연속된 n개의 단어를 하나의 토큰화 단어로 분리해 내는 것이다. n개 단어 크기 윈도우를 만들어 문장의 처음부터 오른쪽으로 움직이면서 토큰화를 수행한다.
스톱 워드 제거
스톱 워드(stop word)는 분석에 큰 의미가 없는 is, the, a 등의 단어를 지칭한다.
NLTK에서 stopwords 목록을 다운받고 스톱워드를 필터링하여 분석을 위한 의미있는 단어만 추출한다.
import nltk
nltk.download('stopwords')
import nltk
stopwords = nltk.corpus.stopwords.words('english')
all_tokens = []
# 위 예제의 3개의 문장별로 얻은 word_tokens list 에 대해 stop word 제거 Loop
for sentence in word_tokens:
filtered_words=[]
# 개별 문장별로 tokenize된 sentence list에 대해 stop word 제거 Loop
for word in sentence:
#소문자로 모두 변환합니다.
word = word.lower()
# tokenize 된 개별 word가 stop words 들의 단어에 포함되지 않으면 word_tokens에 추가
if word not in stopwords:
filtered_words.append(word)
all_tokens.append(filtered_words)
print(all_tokens)[['matrix', 'everywhere', 'around', 'us', ',', 'even', 'room', '.'], ['see', 'window', 'television', '.'], ['feel', 'go', 'work', ',', 'go', 'church', 'pay', 'taxes', '.']]
Stemming과 Lemmatization
Stemming과 Lemmetization은 문법적 또는 의미적으로 변화하는 단어의 원형을 찾는 것이다.
보통 Lemmatization이 Stemming보다 정교하며 의미론적인 기반에서 단어의 원형을 찾는다. 따라서 변환에 더 오랜 시간을 필요로 한다.
from nltk.stem import LancasterStemmer
stemmer = LancasterStemmer()
print(stemmer.stem('working'),stemmer.stem('works'),stemmer.stem('worked'))
print(stemmer.stem('amusing'),stemmer.stem('amuses'),stemmer.stem('amused'))
print(stemmer.stem('happier'),stemmer.stem('happiest'))
print(stemmer.stem('fancier'),stemmer.stem('fanciest'))work work work
amus amus amus
happy happiest
fant fancieststemming의 경우 amuse와 같이 단순한게 변형되는 단어가 아닌 경우 원형 단어를 인식하지 못한다.
또한 비교형, 최상급형의 원형을 찾지 못하는 단점이 있다.
from nltk.stem import WordNetLemmatizer
import nltk
nltk.download('wordnet')
lemma = WordNetLemmatizer()
print(lemma.lemmatize('amusing','v'),lemma.lemmatize('amuses','v'),lemma.lemmatize('amused','v'))
print(lemma.lemmatize('happier','a'),lemma.lemmatize('happiest','a'))
print(lemma.lemmatize('fancier','a'),lemma.lemmatize('fanciest','a'))amuse amuse amuse
happy happy
fancy fancyLemmatization은 정확한 원형 단어 추출을 위해 단어의 품사를 입력해줘야 한다.
추출 결과 더 정확하게 원형 단어를 추출해준다.
03. Bag of Words - BOW
BOW 모델은 문서가 가지는 모든 단어(Words)를 문맥이나 순서를 무시하고 일괄적으로 단어에 대해 빈도값을 부여해 피처 값을 추출하는 모델이다.
쉽고 빠르다는 장점을 가지지만, 단어의 순서를 고려하지 않아 단어의 문맥적인 의미가 무시되고, 희소 행렬 형태의 데이터 세트가 만들어지기 쉬워 ML 알고리즘의 수행 시간과 예측 성능을 떨어뜨릴 수 있다.
이런 단점으로 BOW 기반의 NLP 연구는 여러 제약에 부딪히고 있다.
BOW 피처 벡터화
BOW 모델에서 피처 벡터화를 수행한다는 것은 모든 문서에서 모든 단어를 칼럼 형태로 나열하고 각 문서에서 해당 단어의 횟수나 정규화된 빈도를 값으로 부여하는 데이터 세트 모델로 변경하는 것이다.
즉, N 개의 단어가 있는 M개의 문서를 벡터화 수행 시 MxN 개의 단어 피처로 이루어진 행렬을 구성하게 된다.
피처 벡터화 방식
- 카운트 기반의 벡터화 : 각 문서에서 해당 단어가 나타나는 횟수에 값을 부여한다. 카운트 값이 높을수록 중요한 단어로 인식한다. 문서의 특징을 정확히 나타내기 어렵다.
- TF-IDF 기반의 벡터화 : 개별 문서에서 자주 나타나는 단어에 높은 가중치를 주되, 모든 문서에서 전반적으로 자주 나타나는 단어에 대해서는 패널티를 주는 방식으로 값을 부여한다. 문서마다 텍스트가 길고 문서의 개수가 많은 경우 좋은 예측 성능을 보여준다.
사이킷런의 Count 및 TF-IDF 벡터화 구현: CountVectorizer, TfidfVectorizer
CountVectorizer 클래스는 카운트 기반의 벡터화를 구현한 클래스로, 텍스트 전처리도 함께 수행한다.
fit()과 transform()을 통해 피처 벡터화된 객체를 반환한다.
입력 파라미터
- max_df : 전체 문서에 걸쳐 너무 높은 빈도수를 가지는 단어 피처를 제외한다. 0.95로 설정 시 상위 5%의 피처는 추출하지 않는다.
- min_df : 전체 문서에 걸쳐 너무 낮은 빈도수를 가지는 단어 피처를 제외한다. 0.02로 설정 시 2% 이하의 빈도수를 가지는 피처는 추출하지 않는다.
- max_features : 추출하는 피처의 개수를 제한한다. 2000으로 설정 시 높은 빈도수로 정렬하여 2000개까지만 피처로 추출한다.
- stop_words : 'english'로 지정하면 영어의 스톱워드로 지정된 단어는 추출하지 않는다.
- n_gram_range : BOW 모델의 단어 순서를 보강하지 위한 n_gram 범위를 설정한다. (1,2)로 지정하면 토큰화된 단어를 1개씩 그리고 순서대로 2개씩 묶어서 피처로 추출한다.
- analyzer : 피퍼 추출을 수행할 단위를 지정한다. default='word'이다.
- token_pattern : 토큰화를 수행하는 정규 표현식 패턴을 지정한다. default='\b\w\w+\b'
- tokenizer : 토큰화를 별도의 커스텀 함수로 이용시 적용한다.

TF-IDF 벡터화는 TfidfVectorizer 클래스를 이용하며, 파라미터 변환 방법은 CountVectorizer와 동일하다.
BOW 벡터화를 위한 희소 행렬
위에서 소개한 클래스를 이용해 텍스트를 피처 단위로 벡터화해 변환하고 CSR 형태의 희소 행렬을 반환한다.
희소 행렬은 많은 메모리공간을 차지하므로 COO/CSR 형식으로 희소 행렬이 적은 메모리 공간을 차지하도록 변환한다.
희소 행렬 - COO 형식
COO 형식은 0이 아닌 데이터만 별도의 데이터 배열(Array)에 저장하고, 그 데이터가 가리키는 행과 열의 위치를 별도의 배열로 저장하는 방식이다.
사이파이(Scipy)의 sparse 패키지를 이용하여 희소행렬을 COO형식으로 변환한다.
from scipy import sparse
import numpy as np
dense = np.array( [ [ 3, 0, 1 ], [0, 2, 0 ] ] )
# 0 이 아닌 데이터 추출
data = np.array([3,1,2])
# 행 위치와 열 위치를 각각 array로 생성
row_pos = np.array([0,0,1])
col_pos = np.array([0,2,1])
# sparse 패키지의 coo_matrix를 이용하여 COO 형식으로 희소 행렬 생성
sparse_coo = sparse.coo_matrix((data, (row_pos,col_pos)))
sparse_coo.toarray()array([[3, 0, 1],
[0, 2, 0]])COO 배열은 순차적인 같은 값이 반복적으로 나타나는 문제점이 나타난다.
행 위치 배열의 고유한 값의 시작 위치만 표기하는 방법으로 반복을 제거하는 방식이 CSR 형식이다.
CSR 방식의 변환은 사이파이의 csr_matrix 클래스를 이용해 쉽게 할 수 있다.
from scipy import sparse
dense2 = np.array([[0,0,1,0,0,5],
[1,4,0,3,2,5],
[0,6,0,3,0,0],
[2,0,0,0,0,0],
[0,0,0,7,0,8],
[1,0,0,0,0,0]])
# 0 이 아닌 데이터 추출
data2 = np.array([1, 5, 1, 4, 3, 2, 5, 6, 3, 2, 7, 8, 1])
# 행 위치와 열 위치를 각각 array로 생성
row_pos = np.array([0, 0, 1, 1, 1, 1, 1, 2, 2, 3, 4, 4, 5])
col_pos = np.array([2, 5, 0, 1, 3, 4, 5, 1, 3, 0, 3, 5, 0])
# COO 형식으로 변환
sparse_coo = sparse.coo_matrix((data2, (row_pos,col_pos)))
# 행 위치 배열의 고유한 값들의 시작 위치 인덱스를 배열로 생성
row_pos_ind = np.array([0, 2, 7, 9, 10, 12, 13])
# CSR 형식으로 변환
sparse_csr = sparse.csr_matrix((data2, col_pos, row_pos_ind))
print('COO 변환된 데이터가 제대로 되었는지 다시 Dense로 출력 확인')
print(sparse_coo.toarray())
print('CSR 변환된 데이터가 제대로 되었는지 다시 Dense로 출력 확인')
print(sparse_csr.toarray())COO 변환된 데이터가 제대로 되었는지 다시 Dense로 출력 확인
[[0 0 1 0 0 5]
[1 4 0 3 2 5]
[0 6 0 3 0 0]
[2 0 0 0 0 0]
[0 0 0 7 0 8]
[1 0 0 0 0 0]]
CSR 변환된 데이터가 제대로 되었는지 다시 Dense로 출력 확인
[[0 0 1 0 0 5]
[1 4 0 3 2 5]
[0 6 0 3 0 0]
[2 0 0 0 0 0]
[0 0 0 7 0 8]
[1 0 0 0 0 0]]일반적으로 더 뛰어난 CSR 형식을 많이 사용한다.
04. 텍스트 분류 실습 - 20 뉴스그룹 분류
사이킷런의 fetch_20newsgroups() API를 이용해 뉴스그룹의 분류를 수행한다.
희소 행렬로 변환된 데이터를 효과적으로 분류하는 알고리즘은 로지스틱 회귀, 선형 서포트 벡터 머신, 나이브 베이드 등이 있다.
텍스트 정규화
from sklearn.datasets import fetch_20newsgroups
news_data = fetch_20newsgroups(subset='all',random_state=156)
print(news_data.data[0])From: egreen@east.sun.com (Ed Green - Pixel Cruncher)
Subject: Re: Observation re: helmets
Organization: Sun Microsystems, RTP, NC
Lines: 21
Distribution: world
Reply-To: egreen@east.sun.com
NNTP-Posting-Host: laser.east.sun.com
In article 211353@mavenry.altcit.eskimo.com, maven@mavenry.altcit.eskimo.com (Norman Hamer) writes:
>
> The question for the day is re: passenger helmets, if you don't know for
>certain who's gonna ride with you (like say you meet them at a .... church
>meeting, yeah, that's the ticket)... What are some guidelines? Should I just
>pick up another shoei in my size to have a backup helmet (XL), or should I
>maybe get an inexpensive one of a smaller size to accomodate my likely
>passenger?
If your primary concern is protecting the passenger in the event of a
crash, have him or her fitted for a helmet that is their size. If your
primary concern is complying with stupid helmet laws, carry a real big
spare (you can put a big or small head in a big helmet, but not in a
small one).
---
Ed Green, former Ninjaite |I was drinking last night with a biker,
Ed.Green@East.Sun.COM |and I showed him a picture of you. I said,
DoD #0111 (919)460-8302 |"Go on, get to know her, you'll like her!"
(The Grateful Dead) --> |It seemed like the least I could do...개별 데이터는 위와 같이 구성되어 있다.
이중에서 내요을 데외하고 제목, 작성자, 소속 등의 다른 정보는 제거한다.
remove 파라미터를 이용해 헤더를 제거하고, 순수한 텍스트만드로 구성된 기사 내용으로 어떤 뉴스 그룹에 속하는지 분류한다.
subset 파라미터를 이용해 학습 데이터 세트와 테스트 데이터 세트를 분리해 내려받을 수 있다.
from sklearn.datasets import fetch_20newsgroups
# subset='train'으로 학습용(Train) 데이터만 추출, remove=('headers', 'footers', 'quotes')로 내용만 추출
train_news= fetch_20newsgroups(subset='train', remove=('headers', 'footers', 'quotes'), random_state=156)
X_train = train_news.data
y_train = train_news.target
print(type(X_train))
# subset='test'으로 테스트(Test) 데이터만 추출, remove=('headers', 'footers', 'quotes')로 내용만 추출
test_news= fetch_20newsgroups(subset='test',remove=('headers', 'footers','quotes'),random_state=156)
X_test = test_news.data
y_test = test_news.target
피처 벡터화 변환과 머신러닝 모델 학습/예측/평가
테스트 데이터에서 CountVectorizer를 적용할 때는 반드시 학습 데이터를 이용해 fit()이 수행된 CountVectorizer 객체를 이용해 테스트 데이터를 변환해야한다.
테스트 데이터의 피처 벡터화는 cnt_vect.transform()을 이용해 변환한다.
따라서 fit_transform()을 사용하면 안된다. 이는 테스트 데이터 기반으로 fit()을 수행하고 transform()을 하기 때문에 학습과 예측 데이터 세트의 피처 개수가 달라진다.
from sklearn.feature_extraction.text import CountVectorizer
# Count Vectorization으로 feature extraction 변환 수행.
cnt_vect = CountVectorizer()
cnt_vect.fit(X_train)
X_train_cnt_vect = cnt_vect.transform(X_train)
# 학습 데이터로 fit( )된 CountVectorizer를 이용하여 테스트 데이터를 feature extraction 변환 수행.
X_test_cnt_vect = cnt_vect.transform(X_test)
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
import warnings
warnings.filterwarnings('ignore')
# LogisticRegression을 이용하여 학습/예측/평가 수행.
lr_clf = LogisticRegression(solver='liblinear')
lr_clf.fit(X_train_cnt_vect , y_train)
pred = lr_clf.predict(X_test_cnt_vect)
print('CountVectorized Logistic Regression 의 예측 정확도는 {0:.3f}'.format(accuracy_score(y_test,pred)))CountVectorized Logistic Regression 의 예측 정확도는 0.617
이번에는 TF-IDF 기반으로 벡터화를 변경해 수행한다.
from sklearn.feature_extraction.text import TfidfVectorizer
# TF-IDF Vectorization 적용하여 학습 데이터셋과 테스트 데이터 셋 변환.
tfidf_vect = TfidfVectorizer()
tfidf_vect.fit(X_train)
X_train_tfidf_vect = tfidf_vect.transform(X_train)
X_test_tfidf_vect = tfidf_vect.transform(X_test)
# LogisticRegression을 이용하여 학습/예측/평가 수행.
lr_clf = LogisticRegression(solver='liblinear')
lr_clf.fit(X_train_tfidf_vect , y_train)
pred = lr_clf.predict(X_test_tfidf_vect)
print('TF-IDF Logistic Regression 의 예측 정확도는 {0:.3f}'.format(accuracy_score(y_test ,pred)))TF-IDF Logistic Regression 의 예측 정확도는 0.678TF-IDF 기반이 Count 기반보다 더 예측을 잘 수행하는 것을 알 수 있다.
성능 향상을 위해 TfidVectorizer 클래스의 파라미터를 다양하게 적용시켜본다.
from sklearn.model_selection import GridSearchCV
# 최적 C 값 도출 튜닝 수행. CV는 3 Fold셋으로 설정.
params = { 'C':[0.01, 0.1, 1, 5, 10]}
grid_cv_lr = GridSearchCV(lr_clf ,param_grid=params , cv=3 , scoring='accuracy' , verbose=1 )
grid_cv_lr.fit(X_train_tfidf_vect , y_train)
print('Logistic Regression best C parameter :',grid_cv_lr.best_params_ )
# 최적 C 값으로 학습된 grid_cv로 예측 수행하고 정확도 평가.
pred = grid_cv_lr.predict(X_test_tfidf_vect)
print('TF-IDF Vectorized Logistic Regression 의 예측 정확도는 {0:.3f}'.format(accuracy_score(y_test ,pred)))Fitting 3 folds for each of 5 candidates, totalling 15 fits
Logistic Regression best C parameter : {'C': 10}
TF-IDF Vectorized Logistic Regression 의 예측 정확도는 0.704
사이킷런 파이프라인(Pipeline) 사용 및 GrodSearchCV와의 결합
Pipeline 클래스를 이용하면 피처 벡터화와 ML 알고리즘 학습/예측을 위한 코드 작성을 한 번에 진행할 수 있다.
또한 GridSearchCV의 클래스 생성 파라미터로 Pipeline을 입력해 pipeline 기반에서도 하이퍼 파라미터 튜닝을 GridSearchCV 방식으로 진행할 수 있다.
param_grid 입력값이 딕셔너리 형태의 key와 value 값을 가지며, key 값이 'tfidf_vect_ngram_range'와 같이 하이퍼 파라미터명이 객체 변수명과 결합돼 제공된다.
객체 변수인 tfdir_vect의 ngram_range 파라미터 값을 변화시키면서 최적화하기를 원하면 객체 변수명인 'tfidf_vect'에 언더바 2개를 연달아 붙인 뒤 파라미터 명인 ngram_range를 결합해 key 값으로 할당한다.
from sklearn.pipeline import Pipeline
pipeline = Pipeline([
('tfidf_vect', TfidfVectorizer(stop_words='english')),
('lr_clf', LogisticRegression(solver='liblinear'))
])
# Pipeline에 기술된 각각의 객체 변수에 언더바(_)2개를 연달아 붙여 GridSearchCV에 사용될
# 파라미터/하이퍼 파라미터 이름과 값을 설정. .
params = { 'tfidf_vect__ngram_range': [(1,1), (1,2), (1,3)],
'tfidf_vect__max_df': [100, 300, 700],
'lr_clf__C': [1, 5, 10]
}
# GridSearchCV의 생성자에 Estimator가 아닌 Pipeline 객체 입력
grid_cv_pipe = GridSearchCV(pipeline, param_grid=params, cv=3 , scoring='accuracy',verbose=1)
grid_cv_pipe.fit(X_train , y_train)
print(grid_cv_pipe.best_params_ , grid_cv_pipe.best_score_)
pred = grid_cv_pipe.predict(X_test)
print('Pipeline을 통한 Logistic Regression 의 예측 정확도는 {0:.3f}'.format(accuracy_score(y_test ,pred)))Fitting 3 folds for each of 27 candidates, totalling 81 fits
{'lr_clf__C': 10, 'tfidf_vect__max_df': 700, 'tfidf_vect__ngram_range': (1, 2)} 0.7550828826229531
Pipeline을 통한 Logistic Regression 의 예측 정확도는 0.702다만 이 방식은 매우 많은 튜닝 시간이 소모된다는 단점이 있다.
또한 이 데이터 세트에서는 시간에 비해 큰 정확도 개선이 되지 않았다.
05. 감성 분석
감성 분석 소개
감성 분석(Sentiment Analysis)은 문서의 주관적인 감성/의견/감정 등을 파악하기 위한 방법으로 소셜 미디어, 여론조시, 온라인 리뷰 등 다양한 분야에서 활용되고 있다.
감성 분석은 문서 내 텍스트가 나타내는 여러 가지 주관적인 단어와 문맥을 기반으로 감성(Sentiment) 수치를 계산하는 방법을 이용한다.
이러한 감성 지수는 긍정 감성 지수와 부정 감성 지수로 구성되며 이들을 합산해 긍정 감성 또는 부정 감성을 결정한다.
방식
- 지도학습 : 학습 데이터와 타깃 레이블 값을 기반으로 감성 분석 학습을 한뒤 이를 기반으로 다른 데이터의 감성 분석을 예측한다.
- 비지도학습 : 'Lexicon'이라는 일종의 감성 어휘 사전을 이용하여 문서의 긍정적, 부정적 감성 여부를 판단한다.
지도학습 기반 감성 분석 실습 - IMDB 영화평
영화평의 텍스트를 분석해 감성 분석 결과가 긍정 또는 부정인지 예측한다.
아래 데이터 세트를 이용하였다.
Bag of Words Meets Bags of Popcorn | Kaggle
Bag of Words Meets Bags of Popcorn | Kaggle
www.kaggle.com
사용한 파일은 탭(\t) 문자로 분리된 .tsv 파일로 read_csv의 인자로 seq="\t"를 명시하여 dataframe으로 로딩한다.
import pandas as pd
review_df = pd.read_csv(r"C:\Users\jain5\Desktop\Euron\Data_Handling\labeledTrainData.tsv", header=0, sep="\t", quoting=3)
review_df.head(3)
피처
- id : 각 데이터의 id
- sentiment : 영화평(review)의 Sentiment 결과 값(Terget Label). 1은 긍정적, 0은 부정적 평가를 의미한다.
- review : 영화 평의 텍스트
또한 review 칼럼은 HTML 형식이므로 <br />과 같은 숫자/특수문자를 찾고 이를 공란으로 변환한다.
변환을 위한 문자열 연산은 DataFrame/Series 객체에서 str을 적용한다.
import re
# <br> html 태그는 replace 함수로 공백으로 변환
review_df['review'] = review_df['review'].str.replace('<br />',' ')
# 파이썬의 정규 표현식 모듈인 re를 이용하여 영어 문자열이 아닌 문자는 모두 공백으로 변환
review_df['review'] = review_df['review'].apply( lambda x : re.sub("[^a-zA-Z]", " ", x) )이후 결정 값 클래스를 별도로 추출한 뒤 데이터 세트를 만든다.
from sklearn.model_selection import train_test_split
class_df = review_df['sentiment']
feature_df = review_df.drop(['id','sentiment'], axis=1, inplace=False)
X_train, X_test, y_train, y_test= train_test_split(feature_df, class_df, test_size=0.3, random_state=156)
X_train.shape, X_test.shape((17500, 1), (7500, 1))
이제 review 텍스트를 피처 벡터화 한 후 ML 분류 알고리즘을 적용해 예측 성능을 측정한다.
먼저 Count 벡터화를 적용하였다.
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, roc_auc_score
# 스톱 워드는 English, filtering, ngram은 (1,2)로 설정해 CountVectorization수행.
# LogisticRegression의 C는 10으로 설정.
pipeline = Pipeline([
('cnt_vect', CountVectorizer(stop_words='english', ngram_range=(1,2) )),
('lr_clf', LogisticRegression(solver='liblinear', C=10))])
# Pipeline 객체를 이용하여 fit(), predict()로 학습/예측 수행. predict_proba()는 roc_auc때문에 수행.
pipeline.fit(X_train['review'], y_train)
pred = pipeline.predict(X_test['review'])
pred_probs = pipeline.predict_proba(X_test['review'])[:,1]
print('예측 정확도는 {0:.4f}, ROC-AUC는 {1:.4f}'.format(accuracy_score(y_test ,pred),
roc_auc_score(y_test, pred_probs)))예측 정확도는 0.8860, ROC-AUC는 0.9503
다음은 TF-IDF 벡터화를 적용한다. Pipeline 부분만 달라졌다.
# 스톱 워드는 english, filtering, ngram은 (1,2)로 설정해 TF-IDF 벡터화 수행.
# LogisticRegression의 C는 10으로 설정.
pipeline = Pipeline([
('tfidf_vect', TfidfVectorizer(stop_words='english', ngram_range=(1,2) )),
('lr_clf', LogisticRegression(solver='liblinear', C=10))])
pipeline.fit(X_train['review'], y_train)
pred = pipeline.predict(X_test['review'])
pred_probs = pipeline.predict_proba(X_test['review'])[:,1]
print('예측 정확도는 {0:.4f}, ROC-AUC는 {1:.4f}'.format(accuracy_score(y_test ,pred),
roc_auc_score(y_test, pred_probs)))예측 정확도는 0.8936, ROC-AUC는 0.9598
비지도학습 기반 감성 분석 소개
비지도 감성 분석은 Lexicon을 기반으로 한다.
Lexicon은 결정된 레이블 값을 가지고 있지 않은 경우 유용하게 사용된다.
이 감성 사전은 긍정/부정 감성의 정도를 의미하는 수치(감성지수)를 가지며, 감성 지수는 주변 단어, 문맥, POS 등을 참고해 결정된다.
NLTK 패키지에는 이러한 감성 사전을 구현하고, 여러 서브 모듈을 가진다.
NLTK에서는 WordNet이라는 시맨틱 분석을 제공하는 어휘 사전을 제공한다. 시맨틱 분석을 적용하는 경우, 다양한 상황에서 같은 어휘라도 다르게 사용되는 정보를 제공한다.
NLTK의 감성 사전이 많은 정보를 제공하지만, 예측 성능이 실제로 좋지 못해 실업무에서 사용되지 않는다.
따라서 실제로 사용하는 NLTK를 포함한 감성 사전은 다음과 같다.
- SentiWordNet : WordNet과 유사하게 감성 단어 전용의 WordNet을 구현한 것이다. 3가지 감성 점수(긍정/부정/객관성 지수)를 할당한다.
- VADER : 주로 소셜 미디어의 텍스트에 대한 감성 분석을 제공하기 위한 패키지이다. 뛰어난 감성 분석 결과를 제공하며, 비교적 빠른 수행 시간을 보장해 대용량 텍스트 데이터에 잘 사용되는 패키지이다.
- Pattern : 예측 성능 측면에서 가장 주목받는 패키지이다. 2.X 버전에서만 동작한다...
SentiWordNet을 이용한 감성 분석
nltk.download('all')을 수행하여 NLTK의 모든 데이터 세트와 패키지를 내려받는다.
그 후 WordNet 모듈을 임포트해서 'present' 단어에 대한 Synset을 추출한다.
from nltk.corpus import wordnet as wn
term = 'present'
# 'present'라는 단어로 wordnet의 synsets 생성.
synsets = wn.synsets(term)
print('synsets() 반환 type :', type(synsets))
print('synsets() 반환 값 갯수:', len(synsets))
print('synsets() 반환 값 :', synsets)synsets() 반환 type : <class 'list'>
synsets() 반환 값 갯수: 18
synsets() 반환 값 : [Synset('present.n.01'), Synset('present.n.02'), Synset('present.n.03'), Synset('show.v.01'), Synset('present.v.02'), Synset('stage.v.01'), Synset('present.v.04'), Synset('present.v.05'), Synset('award.v.01'), Synset('give.v.08'), Synset('deliver.v.01'), Synset('introduce.v.01'), Synset('portray.v.04'), Synset('confront.v.03'), Synset('present.v.12'), Synset('salute.v.06'), Synset('present.a.01'), Synset('present.a.02')]Synset 객체의 파라미터 'present.n.0.1'은 POS 태크를 나타낸다. present는 의미, n은 명사 품사, 01은 present가 명사로서 가지는 여러 의미를 구분한다.
Synset 객체는 POS(품사), 정의, 부명제 등의 속성으로 시맨틱 적인 요소를 표현할 수 있다.
WordNet은 어떤 어휘와 다른 어휘 간의 관계를 유사도로 나타낼 수 있다.
이를 위한 path_similarty() 메서드가 있다.
# synset 객체를 단어별로 생성합니다.
tree = wn.synset('tree.n.01')
lion = wn.synset('lion.n.01')
tiger = wn.synset('tiger.n.02')
cat = wn.synset('cat.n.01')
dog = wn.synset('dog.n.01')
entities = [tree , lion , tiger , cat , dog]
similarities = []
entity_names = [ entity.name().split('.')[0] for entity in entities]
# 단어별 synset 들을 iteration 하면서 다른 단어들의 synset과 유사도를 측정합니다.
for entity in entities:
similarity = [ round(entity.path_similarity(compared_entity), 2) for compared_entity in entities ]
similarities.append(similarity)
# 개별 단어별 synset과 다른 단어의 synset과의 유사도를 DataFrame형태로 저장합니다.
similarity_df = pd.DataFrame(similarities , columns=entity_names,index=entity_names)
similarity_df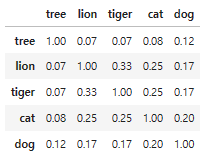
SentiWordNet또한 WordNet의 Syset과 유사한 Senti_Synset 클래스를 가진다.
import nltk
from nltk.corpus import sentiwordnet as swn
senti_synsets = list(swn.senti_synsets('slow'))
print('senti_synsets() 반환 type :', type(senti_synsets))
print('senti_synsets() 반환 값 갯수:', len(senti_synsets))
print('senti_synsets() 반환 값 :', senti_synsets)senti_synsets() 반환 type : <class 'list'>
senti_synsets() 반환 값 갯수: 11
senti_synsets() 반환 값 : [SentiSynset('decelerate.v.01'), SentiSynset('slow.v.02'), SentiSynset('slow.v.03'), SentiSynset('slow.a.01'), SentiSynset('slow.a.02'), SentiSynset('dense.s.04'), SentiSynset('slow.a.04'), SentiSynset('boring.s.01'), SentiSynset('dull.s.08'), SentiSynset('slowly.r.01'), SentiSynset('behind.r.03')]
SentiSynset 객체는 단어의 감성을 나타내는 감성 지수와 객관성을 나타내는 객관성 지수를 가진다. 감성 지수는 다시 긍정 감성 지수와 부정 감성 지수로 나뉜다.
import nltk
from nltk.corpus import sentiwordnet as swn
father = swn.senti_synset('father.n.01')
print('father 긍정감성 지수: ', father.pos_score())
print('father 부정감성 지수: ', father.neg_score())
print('father 객관성 지수: ', father.obj_score())
print('\n')
fabulous = swn.senti_synset('fabulous.a.01')
print('fabulous 긍정감성 지수: ',fabulous .pos_score())
print('fabulous 부정감성 지수: ',fabulous .neg_score())father 긍정감성 지수: 0.0
father 부정감성 지수: 0.0
father 객관성 지수: 1.0
fabulous 긍정감성 지수: 0.875
fabulous 부정감성 지수: 0.125
이제 영화 감상평 감성 분석을 SentiWordNet Lexicon 기반으로 수행한다.
순서
- 문서(Document)를 문장(Sentence)단위로 분해
- 다시 문장을 단어(Word) 단위로 토큰화하고 품사 태깅
- 품사 태깅된 단어 기반으로 synset 객체와 senti_synset 객체를 생성
- senti_synset 객체에서 긍정/부정 감성 지수를 구하고 이를 모두 합산해 긍정/부정 감성 결정
먼저 품사 태깅을 수행하는 내부 함수를 생성한다.
from nltk.corpus import wordnet as wn
# 간단한 NTLK PennTreebank Tag를 기반으로 WordNet기반의 품사 Tag로 변환
def penn_to_wn(tag):
if tag.startswith('J'):
return wn.ADJ
elif tag.startswith('N'):
return wn.NOUN
elif tag.startswith('R'):
return wn.ADV
elif tag.startswith('V'):
return wn.VERB
return
그 다음으로 문서를 문장-> 단어 토큰 -> 품사 태깅 후에 SentiSynset 클래스를 생성하고 Polarity Score를 합산하는 함수를 생성한다.
긍정/부정 감성 지수를 모두 합한 총 감성 지수가 0 이상일 경우 긍정 감성, 그렇지 않을 경우 부정 감성으로 예측한다.
from nltk.stem import WordNetLemmatizer
from nltk.corpus import sentiwordnet as swn
from nltk import sent_tokenize, word_tokenize, pos_tag
def swn_polarity(text):
# 감성 지수 초기화
sentiment = 0.0
tokens_count = 0
lemmatizer = WordNetLemmatizer()
raw_sentences = sent_tokenize(text)
# 분해된 문장별로 단어 토큰 -> 품사 태깅 후에 SentiSynset 생성 -> 감성 지수 합산
for raw_sentence in raw_sentences:
# NTLK 기반의 품사 태깅 문장 추출
tagged_sentence = pos_tag(word_tokenize(raw_sentence))
for word , tag in tagged_sentence:
# WordNet 기반 품사 태깅과 어근 추출
wn_tag = penn_to_wn(tag)
if wn_tag not in (wn.NOUN , wn.ADJ, wn.ADV):
continue
lemma = lemmatizer.lemmatize(word, pos=wn_tag)
if not lemma:
continue
# 어근을 추출한 단어와 WordNet 기반 품사 태깅을 입력해 Synset 객체를 생성.
synsets = wn.synsets(lemma , pos=wn_tag)
if not synsets:
continue
# sentiwordnet의 감성 단어 분석으로 감성 synset 추출
# 모든 단어에 대해 긍정 감성 지수는 +로 부정 감성 지수는 -로 합산해 감성 지수 계산.
synset = synsets[0]
swn_synset = swn.senti_synset(synset.name())
sentiment += (swn_synset.pos_score() - swn_synset.neg_score())
tokens_count += 1
if not tokens_count:
return 0
# 총 score가 0 이상일 경우 긍정(Positive) 1, 그렇지 않을 경우 부정(Negative) 0 반환
if sentiment >= 0 :
return 1
return 0이렇게 생성한 swn_polarity(text) 함수를 이용해 긍정/부정 감성을 예측한다.
판다스의 apply lambda 구문을 이용해 개별 감상평 텍스트에 적용한다.
review_df의 새로운 칼럼으로 'preds'를 추가해 이 칼럼에 반환된 감성 평가를 담았다.
그리고 실제 감성 평가를 이용해 예측 결과의 평가를 수행한다.
review_df['preds'] = review_df['review'].apply( lambda x : swn_polarity(x) )
y_target = review_df['sentiment'].values
preds = review_df['preds'].values
from sklearn.metrics import accuracy_score, confusion_matrix, precision_score
from sklearn.metrics import recall_score, f1_score, roc_auc_score
import numpy as np
print(confusion_matrix( y_target, preds))
print("정확도:", np.round(accuracy_score(y_target , preds), 4))
print("정밀도:", np.round(precision_score(y_target , preds),4))
print("재현율:", np.round(recall_score(y_target, preds), 4))[[7668 4832]
[3636 8864]]
정확도: 0.6613
정밀도: 0.6472
재현율: 0.7091
VADER를 이용한 감성 분석
이번에는 소셜 미디어의 감성 분석 용도로 만들어진 룰 기반의 Lexicon을 이용한다.
여기서는 nltk.download('all')을 이용했으나, 별도 모듈로 셋업을 원하는 OS 상에서 pip install vaderSentimnt로 설치 후 from vaderSentiment.naderSentiment import SentimentIntensityAnalyzer로 임포트하여 사용한다.
VADER를 이용하면 매우 쉽게 감성 분석을 수행할 수 있다.
먼저 객체를 생성한 뒤 문서별로 polarity_scores 메서드를 호출해 감성 점수를 구한 뒤, 해당 문서의 감성 점수가 특정 임계값 이상이면 긍정, 그렇지 않으면 부정으로 판단한다.
polarity_scores() 메서드는 딕셔너리 형태의 감성 점수를 반환한다.
from nltk.sentiment.vader import SentimentIntensityAnalyzer
senti_analyzer = SentimentIntensityAnalyzer()
senti_scores = senti_analyzer.polarity_scores(review_df['review'][0])
print(senti_scores){'neg': 0.13, 'neu': 0.743, 'pos': 0.127, 'compound': -0.7943}
'neg'는 부정 감성 지수, 'neu'는 중립적인 감성 지수, 'pos'는 긍정 감성 지수, 그리고 compound는 neg, neu, pos socre를 적절히 조합해 -1에서 1사이의 감성 지수를 표현한 값이다. 이 score를 기반으로 부정 감성 또는 긍정 감성 여부를 결정한다.
def vader_polarity(review,threshold=0.1):
analyzer = SentimentIntensityAnalyzer()
scores = analyzer.polarity_scores(review)
# compound 값에 기반하여 threshold 입력값보다 크면 1, 그렇지 않으면 0을 반환
agg_score = scores['compound']
final_sentiment = 1 if agg_score >= threshold else 0
return final_sentiment
# apply lambda 식을 이용하여 레코드별로 vader_polarity( )를 수행하고 결과를 'vader_preds'에 저장
review_df['vader_preds'] = review_df['review'].apply( lambda x : vader_polarity(x, 0.1) )
y_target = review_df['sentiment'].values
vader_preds = review_df['vader_preds'].values
print(confusion_matrix( y_target, vader_preds))
print("정확도:", np.round(accuracy_score(y_target , vader_preds),4))
print("정밀도:", np.round(precision_score(y_target , vader_preds),4))
print("재현율:", np.round(recall_score(y_target, vader_preds),4))[[ 6747 5753]
[ 1858 10642]]
정확도: 0.6956
정밀도: 0.6491
재현율: 0.8514정확도가 SentiWordNet보다 향상됐고, 특히 재현율이 매우 크게 향상됐음을 알 수 있다.
#회고
여러 NLP 패키지가 한국어를 지원하지 않는다거나..언어 관련 인공지능을 공부하니까 확실히 영어의 편리함이 느껴졌다..
참 재밌는 것 같다. 기계가 감정을 분석하는거..
이번 과제는 기본적으로 내려받을 패키지가 많아서 시간이 꽤 걸렸다.
'Euron > 정리' 카테고리의 다른 글
| [Week16] 08. 텍스트 분석 - 실습 (2) | 2023.12.22 |
|---|---|
| [Week12] Popular Unsupervised Clustering Algorithms (0) | 2023.12.18 |
| [Week12] 07. 군집화 실습 - 고객 세그먼테이션 (0) | 2023.11.22 |
| [Week11] 07. 군집화(2) (0) | 2023.11.15 |
| [Week11] 07. 군집화(1) (0) | 2023.11.15 |



