고객 세그먼테이션의 정의와 기법
고객 세그먼테이션(customer Segmentation)은 다양한 기준으로 고객을 분류하는 기법을 지칭한다.
주요 분류 요소는 어떤 상품을 얼마나 많은 비용을 써서 얼마나 자주 사용하는가에 기반한 정보이다.
고객 세그먼테이션의 주요 목표는 타깃 마케팅이다. 기업의 마케팅은 고객의 상품 구매 이력에서 출발한다.
기본적인 고객 분석 요소인 RFM 기법을 이용한다.
- Recency : 가장 최근 상품 구입 일에서 오늘까지의 기간
- Frequency : 상품 구매 횟수
- Monetary value : 총 구매 금액
데이터 세트 로딩과 데이터 클렌징

- InvoiceNo: 주문번호. 'C'로 시작하는 것은 취소 주문이다.
- StockCode: 제품 코드
- Description: 제품 설명
- Quantity: 주문 제품 건수
- InvoiceDate: 주문 일자
- UnitPriceL 제품 단가
- CustomerID: 고객 번호
- Country: 국가명(주문 고객의 국적)
해당 데이터는 Null값이 존재하는 컬럼이 있고, 다른 칼럼의 경우 오류 데이터가 존재하므로 사전 정제 작업이 필요하다.
# Null 데이터 삭제
retail_df = retail_df[retail_df['Quantity'] > 0]
retail_df = retail_df[retail_df['UnitPrice'] > 0]
retail_df = retail_df[retail_df['CustomerID'].notnull()]
print(retail_df.shape)
retail_df.isnull().sum()
# 영국을 제외한 국가 데이터 삭제
retail_df = retail_df[retail_df['Country']=='United Kingdom']
RFM 기반 데이터 가공
UnitPrice와 Quantity 칼럼을 곱해 주문 금액 데이터를 만든다.
CustomerNo 컬럼을 식별을 위해 int형으로 바꾼다.
retail_df['sale_amount'] = retail_df['Quantity'] * retail_df['UnitPrice']
retail_df['CustomerID'] = retail_df['CustomerID'].astype(int)
주어진 데이터 세트는 주문번호(InvoiceNo) + 상품코드(StockCode) 레벨의 식별자로 돼있다.
개별 고객 기준으로 InvoiceNo+StockCode로 Groupby 후 RFM 데이터로 가공한다.
# DataFrame의 groupby() 의 multiple 연산을 위해 agg() 이용
# Recency는 InvoiceDate 컬럼의 max() 에서 데이터 가공
# Frequency는 InvoiceNo 컬럼의 count() , Monetary value는 sale_amount 컬럼의 sum()
aggregations = {
'InvoiceDate': 'max',
'InvoiceNo': 'count',
'sale_amount':'sum'
}
cust_df = retail_df.groupby('CustomerID').agg(aggregations)
# groupby된 결과 컬럼값을 Recency, Frequency, Monetary로 변경
cust_df = cust_df.rename(columns = {'InvoiceDate':'Recency',
'InvoiceNo':'Frequency',
'sale_amount':'Monetary'
}
)
cust_df = cust_df.reset_index()
cust_df.head(3)
groupby를 호출해 반환된 DataFrameGroupby 객체에 agg()를 이용한다.
agg()에 인자로 대상 칼럼들과 aggregation 함수명들을 딕셔너리 형태로 입력하면 칼럼 여러 개의 서로 다른 aggregation연산을 쉽게 수행할 수 있다.
import datetime as dt
cust_df['Recency'] = dt.datetime(2011,12,10) - cust_df['Recency']
cust_df['Recency'] = cust_df['Recency'].apply(lambda x: x.days+1)
print('cust_df 로우와 컬럼 건수는 ',cust_df.shape)
cust_df.head(3)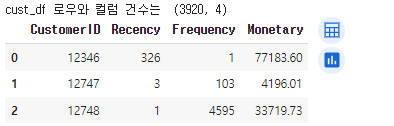
Recency를 구하기 위해 온라인 판매 마지막 날에 +1한 데이터에서 고객이 가장 최근에 주문한 날짜를 구한 후 일자 데이터(days)만 추출해 생성한다.
RFM 기반 고객 세그멘테이션
해당 데이터는 소매업체의 대규모 주문을 포함하므로 군집화가 한쪽 군집에만 집중되는 왜곡화 현상이 발생한다.
먼저 왜곡을 완화시키기 위해 데이터 세트를 StandardSacler로 평균과 표준 편차를 재조정한 귀 K-평균을 수행한다.
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score, silhouette_samples
X_features = cust_df[['Recency','Frequency','Monetary']].values
X_features_scaled = StandardScaler().fit_transform(X_features)
kmeans = KMeans(n_clusters=3, random_state=0)
labels = kmeans.fit_predict(X_features_scaled)
cust_df['cluster_label'] = labels
print('실루엣 스코어는 : {0:.3f}'.format(silhouette_score(X_features_scaled,labels)))
visualize_silhouette([2,3,4,5],X_features_scaled)
visualize_kmeans_plot_multi([2,3,4,5],X_features_scaled)
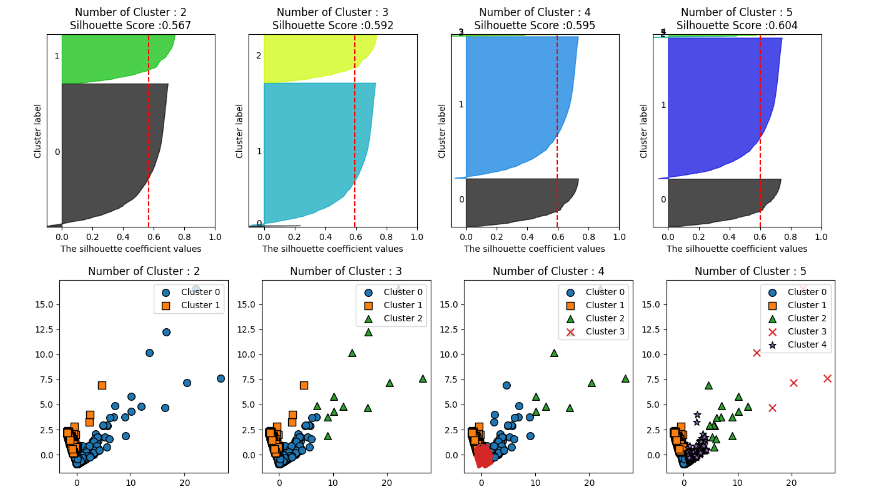
실루엣 계수는 0.592로 안정적인 수치가 나왔다.
그러나 시각화 결과 군집에 속한 데이터 개수가 너무 작은 군집이 만들어졌다.
군집이 3개일 때, 0번 데이터 세트의 개수가 너무 적다. 군집이 4개일 때는 2,3번 군집, 5개일 때는 2,3,4번의 군집에 속한 데이터 개수가 너무 적다.
이 데이터 세트는 데이터 값이 거리 기반으로 광범위하게 퍼져 있어 군집 수를 계속 늘려도 의미 없는 결과로 이어진다.
이러한 데이터 세트의 왜곡 정도를 낮추기 위해 자주 사용되는 방법은 데이터 값에 로그(log)를 적용하는 것이다.
### Log 변환을 통해 데이터 변환
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score, silhouette_samples
# Recency, Frequecny, Monetary 컬럼에 np.log1p() 로 Log Transformation
cust_df['Recency_log'] = np.log1p(cust_df['Recency'])
cust_df['Frequency_log'] = np.log1p(cust_df['Frequency'])
cust_df['Monetary_log'] = np.log1p(cust_df['Monetary'])
# Log Transformation 데이터에 StandardScaler 적용
X_features = cust_df[['Recency_log','Frequency_log','Monetary_log']].values
X_features_scaled = StandardScaler().fit_transform(X_features)
kmeans = KMeans(n_clusters=3, random_state=0)
labels = kmeans.fit_predict(X_features_scaled)
cust_df['cluster_label'] = labels
print('실루엣 스코어는 : {0:.3f}'.format(silhouette_score(X_features_scaled,labels)))
visualize_silhouette([2,3,4,5],X_features_scaled)
visualize_kmeans_plot_multi([2,3,4,5],X_features_scaled)

실루엣 스코어는 로그 변환 전보다 떨어진다.
그러나 시각화 결과 앞의 경우보다 더 균일하게 군집화가 구성됐음을 알 수 있다.
# 정리
머신러닝 기반의 군집화 기법에 대해 배웠다.
- K-Means : 거리 기반으로 군집 중심점을 이동시키면서 군집화를 수행
- 매우 쉽고 직관적인 알고리즘으로 많은 군집화에 사용되지만, 복잡한 구조를 가지는 데이터 세트에 적용하기에는 한계가 있으며, 군집의 개수를 최적화하기가 어렵다.
- K-평균은 군집이 잘 되었는지의 평가를 위해 실루엣 계수를 이용한다.
- Mean Shift : K-평균과 유사하지만 거리 중심이 아니라 데이터가 모여 있는 밀도가 가장 높은 쪽으로 군집 중심점을 이동하면서 군집화를 수행한다.
- 컴퓨터 비전 영역에서 이미지나 영상 데이터에서 특정 개체를 구분하거나 움직임을 추적하는 데 뛰어난 역할을 수행하는 알고리즘이다.
- GMM : 군집화를 적용하고자 하는 데이터가 여러 개의 가우시안 분포를 모델을 섞어서 생성된 모델로 가정해 수행하는 방식이다.
- 전체 데이터 세트에서 서로 다른 정규 분포 형태를 추출해 다른 정규 분포를 가진 데이터 세트를 각각 군집화하는 것이다.
- K-평균보다 유연하게 다양한 데이터 세트에 잘 적용될 수 있다.
- 군집화를 위한 수행 시간이 오래걸린다.
- DBSCAN : 밀도 기반 군집화의 대표적인 알고리즘이다.
- 입실론 주변 영역 내에 포함되는 최소 데이터 개수의 충족 여부에 따라 데이터 포인트를 구분하고 특정 핵심 포인트에서 직접 접근이 가능한 다른 핵심 포인트를 서로 연결하면셔 군집화를 구성한다.
- 데이터의 분포가 기하학적으로 복잡한 데이터 세트에도 효과적인 군집화가 가능하다.
'Euron > 정리' 카테고리의 다른 글
| [Week12] Popular Unsupervised Clustering Algorithms (0) | 2023.12.18 |
|---|---|
| [Week15] 08. 텍스트 분석 (1) | 2023.12.18 |
| [Week11] 07. 군집화(2) (0) | 2023.11.15 |
| [Week11] 07. 군집화(1) (0) | 2023.11.15 |
| [Week 8] 🥑💰 PyCaret 및 EDA를 사용한 아보카도 가격 회귀 💹 (0) | 2023.11.06 |



