SQL 코딩 테스트 대비 연습. 일단 기초부터 다시 연습한다.
https://school.programmers.co.kr/learn/challenges?tab=sql_practice_kit
프로그래머스
SW개발자를 위한 평가, 교육, 채용까지 Total Solution을 제공하는 개발자 성장을 위한 베이스캠프
programmers.co.kr
1. 3월에 태어난 여성 회원 목록 출력하기
-- 코드를 입력하세요
SELECT MEMBER_ID, MEMBER_NAME, GENDER, DATE_FORMAT(DATE_OF_BIRTH, "%Y-%m-%d") AS DATE_OF_BIRTH FROM MEMBER_PROFILE WHERE TLNO IS NOT NULL AND MONTH(DATE_OF_BIRTH)=3 AND GENDER='W' ORDER BY MEMBER_ID ASC;- DATE TYPE의 정확한 출력을 위해 DATE_FORMAT을 지정해준다. m과 d 소문자로 작성 주의!
- NULL값 비교는 IS NULL / IS NOT NULL
- MONTH()를 이용해서 월을 비교할 때, return 값은 정수형이므로 03이 아닌 3으로 작성한다.
- SQL에서는 비교연산자 = 사용
- ORDER BY 에서 ASC는 오름차순, DESC는 내림차순
2. 재구매가 일어난 상품과 회원 리스트 구하기
-- 코드를 입력하세요
SELECT USER_ID, PRODUCT_ID FROM ONLINE_SALE GROUP BY USER_ID, PRODUCT_ID HAVING COUNT(*)>1 ORDER BY USER_ID ASC, PRODUCT_ID DESC;- GROUP BY와 HAVING 절을 사용하여 데이터를 그룹 단위로 집계한다.
- HAVING 함수 : COUNT, SUM, AVG, MAX, MIN 등
- ORDER BY 정렬 조건을 추가 하고 싶은 경우 , 를 이용해 추가한다.
3. 역순 정렬하기
-- 코드를 입력하세요
SELECT NAME, DATETIME FROM ANIMAL_INS ORDER BY ANIMAL_ID DESC;
4. 아픈 동물 찾기
-- 코드를 입력하세요
SELECT ANIMAL_ID, NAME FROM ANIMAL_INS WHERE INTAKE_CONDITION = 'Sick'
5. 어린 동물 찾기
-- 코드를 입력하세요
SELECT ANIMAL_ID, NAME FROM ANIMAL_INS WHERE INTAKE_CONDITION != 'Aged';- 만약 같지 않음을 비교하고 싶으면 != 혹은 <> 사용
6. 동물의 아이디와 이름
-- 코드를 입력하세요
SELECT ANIMAL_ID, NAME FROM ANIMAL_INS;
7. 여러 기준으로 정렬하기
-- 코드를 입력하세요
SELECT ANIMAL_ID, NAME, DATETIME FROM ANIMAL_INS ORDER BY NAME, DATETIME DESC;- SQL에서 기본 정렬은 ASC
8. 상위 n개 레코드
-- 코드를 입력하세요
SELECT NAME FROM ANIMAL_INS ORDER BY DATETIME LIMIT 1;- 상위 N개의 레코드만 조회하기 위해서는 LIMIT N 을 이용한다.
9. 조건에 맞는 회원수 구하기
-- 코드를 입력하세요
SELECT COUNT(*) AS USERS FROM USER_INFO WHERE AGE BETWEEN 20 AND 29 AND YEAR(JOINED)=2021;- 사잇 값을 비교할 때에는 BETWEEN a AND b 를 사용한다.
10. 서울에 위치한 식당 목록 출력하기
SELECT ri.REST_ID,
ri.REST_NAME,
ri.FOOD_TYPE,
ri.FAVORITES,
ri.ADDRESS,
rr.SCORE
FROM REST_INFO AS ri
JOIN
(SELECT REST_ID, ROUND(AVG(REVIEW_SCORE),2) AS SCORE
FROM REST_REVIEW
GROUP BY REST_ID) rr
USING(REST_ID)
WHERE ri.ADDRESS LIKE '서울%'
ORDER BY rr.SCORE DESC, ri.FAVORITES DESC;- 서브쿼리를 이용하는 방식. REST_REVIEW 테이블에서 SCORE의 평균(AVG)을 소숫점 둘째자리까지 반올림 후(ROUND) 별칭 rr로 SELECT한다.
- 이때 JOIN과 USING을 이용하여 REST_ID를 기준으로 조인한다. USING 대신 ON ri.REST_ID = rr.REST_ID 으로 조인할 수 있다.
- ri 테이블의 주소 비교를 위해 LIKE 및 %와일드카드를 이용한다.
SELECT ri.REST_ID,
ri.REST_NAME,
ri.FOOD_TYPE,
ri.FAVORITES AS FAVORITE,
ri.ADDRESS,
ROUND(AVG(REVIEW_SCORE),2) AS SCORE
FROM REST_INFO AS ri
INNER JOIN REST_REVIEW AS rr USING(REST_ID)
WHERE ri.ADDRESS LIKE '서울%'
GROUP BY REST_ID
ORDER BY SCORE DESC, FAVORITE DESC;- INNER JOIN을 이용한 방식.
- JOIN과 다르게 테이블을 결합한 후 계산한다.
- 평균적으로는 INNER JOIN 방식이 더 빠르지만, REST_REVIEW TABLE이 큰 경우 JOIN + 서브 쿼리가 더 성능이 좋을 수 있다.
11. 흉부외과 또는 일반외과 의사 목록 출력하기
-- 코드를 입력하세요
SELECT DR_NAME, DR_ID, MCDP_CD, DATE_FORMAT(HIRE_YMD, "%Y-%m-%d") FROM DOCTOR WHERE MCDP_CD IN ('CS', 'GS') ORDER BY HIRE_YMD DESC, DR_NAME ASC;- 특정 값을 비교할 때 OR을 사용해도 되지만, IN(값) 을 사용할 수도 있다.
12. 과일로 만든 아이스크림 고르기
-- 코드를 입력하세요
SELECT FLAVOR FROM FIRST_HALF WHERE FLAVOR IN (SELECT FLAVOR FROM ICECREAM_INFO WHERE INGREDIENT_TYPE='fruit_based') AND TOTAL_ORDER > 3000 ORDER BY TOTAL_ORDER DESC;- 서브쿼리를 이용한 방식
SELECT F_H.FLAVOR
FROM FIRST_HALF AS F_H
INNER JOIN ICECREAM_INFO AS I_I
ON F_H.FLAVOR = I_I.FLAVOR
WHERE TOTAL_ORDER > 3000 AND INGREDIENT_TYPE = 'fruit_based';- INNER JOIN 이용한 방식
- 난 서브 쿼리가 더 익숙해서 좋은데...INNER JOIN에 익숙해져야됨
13. 평균 일일 대여 요금 구하기
-- 코드를 입력하세요
SELECT ROUND(AVG(DAILY_FEE), 0) AS AVERAGE_FEE FROM CAR_RENTAL_COMPANY_CAR WHERE CAR_TYPE='SUV';
14. 강원도에 위치한 생산공장 목록 출력하기
-- 코드를 입력하세요
SELECT FACTORY_ID, FACTORY_NAME, ADDRESS FROM FOOD_FACTORY WHERE ADDRESS LIKE "강원도%";
15. 인기있는 아이스크림
-- 코드를 입력하세요
SELECT FLAVOR FROM FIRST_HALF ORDER BY TOTAL_ORDER DESC, SHIPMENT_ID;
16. 12세 이하인 여아 환자 목록 출력하기
-- 코드를 입력하세요
SELECT PT_NAME, PT_NO, GEND_CD, AGE, IFNULL(TLNO,'NONE') AS TLNO FROM PATIENT WHERE AGE<=12 AND GEND_CD='W' ORDER BY AGE DESC, PT_NAME ASC;- NULL 조건 검사 후 출력인 경우 IFNULL함수 이용하기
- 별칭 및 출력값 주의...
17. 조건에 맞는 도서 리스트 출력하기
-- 코드를 입력하세요
SELECT BOOK_ID, DATE_FORMAT(PUBLISHED_DATE, "%Y-%m-%d") AS PUBLISHED_DATE FROM BOOK WHERE YEAR(PUBLISHED_DATE)=2021 AND CATEGORY='인문' ORDER BY PUBLISHED_DATE;
18. 조건에 부합하는 중고거래 댓글 조회하기
-- 코드를 입력하세요
SELECT B.TITLE, B.BOARD_ID, R.REPLY_ID, R.WRITER_ID, R.CONTENTS, DATE_FORMAT(R.CREATED_DATE, "%Y-%m-%d") AS CREATED_DATE FROM USED_GOODS_BOARD AS B INNER JOIN USED_GOODS_REPLY AS R USING(BOARD_ID) WHERE DATE_FORMAT(B.CREATED_DATE, "%Y-%m") ='2022-10' ORDER BY R.CREATED_DATE ASC, B.TITLE ASC;- 동일한 CREATED_DATE 컬럼명 주의.
- DATE 타입을 비교할 때 DATE_FORMAT()을 이용해 문자열로 비교하는 방법으로 년과 월을 한 번에 비교할 수 있다.
- INNER JOIN & USING 을 이용했다.
19. 모든 레코드 조회하기
-- 코드를 입력하세요
SELECT * FROM ANIMAL_INS;- * 와일드카드를 이용해 전부 조회하기
- DEFAULT는 첫번째 컬럼(ID) 오름차순으로 정렬
20. 오프라인/온라인 판매 데이터 통합하기
SELECT DATE_FORMAT(SALES_DATE, "%Y-%m-%d") AS SALES_DATE, PRODUCT_ID, USER_ID, SALES_AMOUNT
FROM ONLINE_SALE
WHERE SALES_DATE BETWEEN '2022-03-01' AND '2022-03-31'
UNION ALL
SELECT DATE_FORMAT(SALES_DATE, "%Y-%m-%d") AS SALES_DATE, PRODUCT_ID, NULL AS USER_ID, SALES_AMOUNT
FROM OFFLINE_SALE
WHERE SALES_DATE BETWEEN '2022-03-01' AND '2022-03-31'
ORDER BY SALES_DATE ASC, PRODUCT_ID ASC, USER_ID ASC;- UNION 을 사용해 두 쿼리 결과를 결합한다. UNION ALL 은 중복된 결과를 제거하지 않을 때 사용하는데, 이 문제에서는 중복되는 경우가 없었음.
- UNION을 사용할 때는 두 쿼리 결과의 컬럼 수 및 데이터 타입이 같아야 한다!(컬럼명은 달라도 상관 없음. 첫번째 쿼리문의 컬럼명 사용)
21. 업그레이드 된 아이템 구하기
select t.ITEM_ID, i.ITEM_NAME, i.RARITY
from ITEM_INFO i
join ITEM_TREE t on i.ITEM_ID = t.ITEM_ID
where PARENT_ITEM_ID in (SELECT ITEM_ID FROM ITEM_INFO WHERE RARITY = 'RARE')
order by ITEM_ID desc;- 조인과 서브쿼리를 이용한 방식
- AS가 없어도 별칭 지정 가능
22. Python 개발자 찾기
-- 코드를 작성해주세요
SELECT ID, EMAIL, FIRST_NAME, LAST_NAME FROM DEVELOPER_INFOS WHERE SKILL_1='Python' or SKILL_2='Python' or SKILL_3='Python' ORDER BY ID;SELECT ID, EMAIL, FIRST_NAME, LAST_NAME
FROM DEVELOPER_INFOS
WHERE 'Python' IN (SKILL_1, SKILL_2, SKILL_3)
ORDER BY ID;- OR 대신 IN을 사용하여 더 간단하게 바꿀 수 있음
23. 조건에 맞는 개발자 찾기
SELECT
DISTINCT id,
email,
first_name,
last_name
FROM
developers
WHERE
skill_code & (SELECT SUM(code) FROM skillcodes WHERE name IN ('C#', 'Python'))
ORDER BY
1- 비트 연산자 & 활용! CODE의 SUM을 비트 연산결과를 만족하는 조건만 SELECT한다.
- 예를 들어, SUM(CODE) = 0011이고 SKILL_CODE & 0011 값이 0 이 나오지 않기 위해서는 10 또는 01을 포함해야 한다는 뜻!
- DISTINCT로 중복 없애기
24. 잔챙이 잡은 수 구하기
-- 코드를 작성해주세요
SELECT COUNT(*) FISH_COUNT FROM FISH_INFO WHERE LENGTH IS NULL;
25. 가장 큰 물고기 10마리 구하기
-- 코드를 작성해주세요
SELECT ID, LENGTH FROM FISH_INFO ORDER BY LENGTH DESC, ID ASC LIMIT 10;
26. 특정 물고기를 잡은 총 수 구하기
-- 코드를 작성해주세요
SELECT COUNT(*) FISH_COUNT FROM FISH_INFO WHERE FISH_TYPE IN (SELECT FISH_TYPE FROM FISH_NAME_INFO WHERE FISH_NAME IN ('SNAPPER', 'BASS'));
27. 대장균들의 자식의 수 구하기
-- 코드를 작성해주세요
SELECT ID, (SELECT COUNT(*) FROM ECOLI_DATA WHERE PARENT_ID=E.ID) AS CHILD_COUNT FROM ECOLI_DATA AS E ORDER BY ID;- 같은 테이블을 사용하므로, 구분을 위해 테이블의 별칭을 이용해야 한다.
- 각 행 E.ID 에 대하여 서브쿼리를 수행하고, 수행한 결과를 COUNT() 후 반환한다.
28. 대장균의 크기에 따라 구분하기
-- 코드를 작성해주세요
SELECT ID, CASE
WHEN SIZE_OF_COLONY <=100 THEN 'LOW'
WHEN SIZE_OF_COLONY <=1000 THEN 'MEDIUM'
ELSE 'HIGH'
END
AS SIZE
FROM ECOLI_DATA
ORDER BY ID;- 다중 조건문(CASE) 사용하기!
- CASE~END 구문 안에 WHEN '조건' THEN '반환' 을 작성해 조건에 따라 반환한다.
- IF(조건, 참, 거짓) 에서 거짓 안에 IF문을 중첩하여 작성할 수도 있다. 가독성이 떨어지므로 추천 X
29. 특정 형질을 가지는 대장균 찾기
SELECT COUNT(*) AS COUNT
FROM ECOLI_DATA
WHERE (GENOTYPE & 0b10) = 0 -- 2번 형질을 보유하지 않음
AND (GENOTYPE & 0b101) > 0; -- 1번 또는 3번 형질을 보유함- 비트 연산자(&)를 이용해서 보유 형질 찾기
- N번 형질인 경우 N번째 비트가 1인것....즉 3번 형질이면 0100==8이 된다.....이 부분이 너무 복잡했다.
- 이진수로 계산할 때는 0b를 앞에 붙여주기, 아니면 10진수로 비트 연산 해주기
30. 부모의 형질을 모두 가지는 대장균 찾기
-- 코드를 작성해주세요
SELECT ID, GENOTYPE, (SELECT GENOTYPE FROM ECOLI_DATA WHERE ID=E.PARENT_ID) AS PARENT_GENOTYPE
FROM ECOLI_DATA AS E
WHERE GENOTYPE&(SELECT GENOTYPE FROM ECOLI_DATA WHERE ID=E.PARENT_ID) >= (SELECT GENOTYPE FROM ECOLI_DATA WHERE ID = E.PARENT_ID)
ORDER BY ID;- 부모의 형질을 모두 가진 다는 것은 부모의 형질과 자신의 형질을 비트 연산 했을 때의 값이 부모의 형질보다 커야 한다.
- 서브 쿼리를 이용해 부모 형질을 따로 추출함
SELECT
E.ID,
E.GENOTYPE,
P.GENOTYPE AS PARENT_GENOTYPE
FROM
ECOLI_DATA AS E
JOIN
ECOLI_DATA AS P ON E.PARENT_ID = P.ID
WHERE
E.GENOTYPE & P.GENOTYPE >= P.GENOTYPE
ORDER BY
E.ID;- 반복해서 서브쿼리를 추출하고 있으므로, 더 효율적으로 SELECT 하기 위해 JOIN을 사용해 PARENT의 형질을 가져올 수 있다.
31. 대장균의 크기에 따라 구분하기2
-- 코드를 작성해주세요
SELECT
ID,
CASE
WHEN PERCENTILE <= 1 THEN 'CRITICAL'
WHEN PERCENTILE <= 2 THEN 'HIGH'
WHEN PERCENTILE <= 3 THEN 'MEDIUM'
ELSE 'LOW'
END AS COLONY_NAME
FROM (
SELECT
ID,
SIZE_OF_COLONY,
NTILE(4) OVER (ORDER BY SIZE_OF_COLONY DESC) AS PERCENTILE
FROM ECOLI_DATA
) AS SUBQUERY
ORDER BY ID;- WINDOW 함수 NTILE을 이용해 N개의 그룹으로 나눈 후 PERCENTILE 별칭을 붙인다.
- NTILE은 그룹을 상위부터 1, 2, 3, ... RANK를 붙이므로, 이를 이용해 CASE~END 구문을 이용해 NAME을 나눈다.
- 아래와 같이 PERENTILE 컬럼 추가
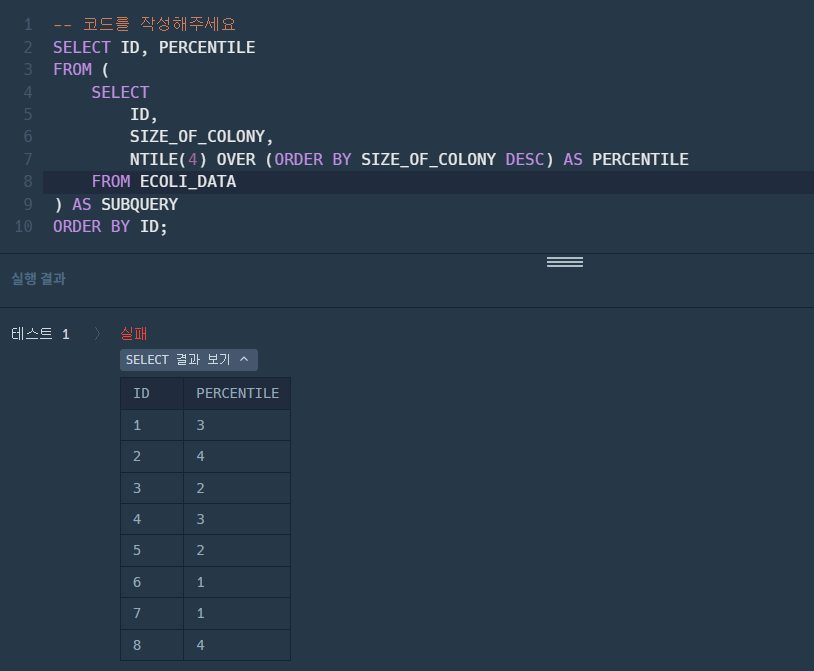
- RANK값이 PERCENTILE 컬럼에 들어갔따.
SELECT
ID,
CASE
WHEN RANK <= (SELECT COUNT(*) / 4 FROM ECOLI_DATA) THEN 'CRITICAL'
WHEN RANK <= (SELECT COUNT(*) / 2 FROM ECOLI_DATA) THEN 'HIGH'
WHEN RANK <= (SELECT COUNT(*) * 3 / 4 FROM ECOLI_DATA) THEN 'MEDIUM'
ELSE 'LOW'
END AS COLONY_NAME
FROM (
SELECT
ID,
SIZE_OF_COLONY,
ROW_NUMBER() OVER (ORDER BY SIZE_OF_COLONY DESC) AS RANK
FROM ECOLI_DATA
) AS SUBQUERY
ORDER BY ID;- ROW_NUMBER() WINDOW 함수를 이용한 방식
- OVER() 과 함께 사용하며, 집계된 각 행에 대해 고유한 순위 번호를 부여한다.
- RANK()와 다르게, 같은 값에도 다른 순위 번호를 부여한다.
- MySQL은 CASE 구문에 서브 쿼리를 사용할 수 없으므로...외부 별칭을 사용해야 한다.
32. 특정 세대의 대장균 찾기
-- 코드를 작성해주세요
SELECT ID FROM ECOLI_DATA
WHERE PARENT_ID IN (SELECT ID FROM ECOLI_DATA
WHERE PARENT_ID IN (SELECT ID FROM ECOLI_DATA WHERE PARENT_ID IS NULL))
ORDER BY ID;- 3세대..세대가 작아서 서브 쿼리를 중첩하여 해결했다.
- 만약 세대가 커진다면 -> 재귀 사용(시러....)
WITH RECURSIVE Generations AS (
-- 첫 번째 세대 (부모가 NULL인 개체)
SELECT ID, PARENT_ID, 1 AS Generation
FROM ECOLI_DATA
WHERE PARENT_ID IS NULL
UNION ALL
-- 그 다음 세대 (PARENT_ID가 이전 세대의 ID에 해당하는 개체)
SELECT e.ID, e.PARENT_ID, g.Generation + 1
FROM ECOLI_DATA e
INNER JOIN Generations g ON e.PARENT_ID = g.ID
)
SELECT ID
FROM Generations
WHERE Generation = 3
ORDER BY ID;- 재귀적 쿼리(CTE)를 사용한 방식
- WITH RECURSIVE 를 이용해 CTE를 정의한다. Generation은 CTE의 이름이 되며, 각 객체의 세대를 추적하는데 사용된다.
- 첫 번째 구문에는 기본 조건으로 시작되는 부분으로, 가장 상위 레벨의 데이터를 가져온다.
- UNION ALL을 이용해 기본 조건과 재귀 반복 조건을 결합한다.
- 두 번째 구문에는 하위 데이터를 찾는 조건을 작성한다. JOIN 을 이용해 이전 세대(Generation)의 ID를 PARENT_ID로 가지는 현재 테이블을 SELECT 한다.
- 최종 SELECT에서는 Generation=3을 조건으로 SELECT 한다.
- 참고로 기본적으로 MySQL에서 재귀는 100번만 허용하며, 이후는 설정 값을 직접 조절해야함
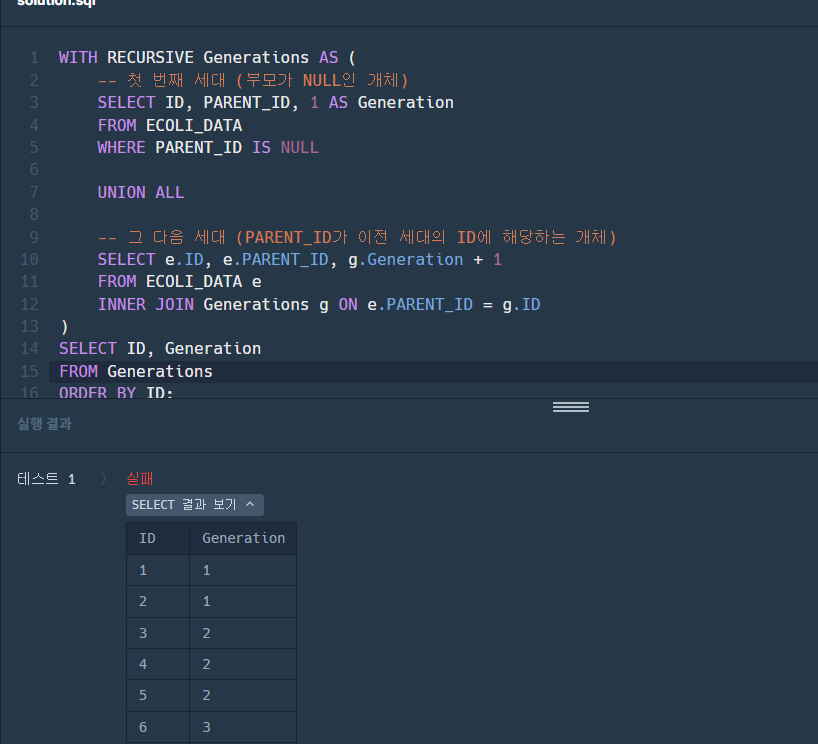
- 각 재귀(Generation) 별 SELECT된 ID 값들을 확인할 수 있다.
33. 멸종 위기의 대장균 찾기
WITH RECURSIVE Generation AS (
-- 첫 번째 세대 (부모)
SELECT ID, PARENT_ID, 1 AS GENERATION
FROM ECOLI_DATA
WHERE PARENT_ID IS NULL
UNION ALL
-- 자식 세대 계산
SELECT e.ID, e.PARENT_ID, g.GENERATION + 1 AS GENERATION
FROM ECOLI_DATA e
JOIN Generation g ON e.PARENT_ID = g.ID
)
-- 자식이 없는 개체의 수를 카운트
SELECT COUNT(g.ID) AS COUNT, g.GENERATION
FROM Generation g
LEFT JOIN ECOLI_DATA e ON g.ID = e.PARENT_ID
WHERE e.PARENT_ID IS NULL -- 자식이 없는 개체만 필터링
GROUP BY g.GENERATION
ORDER BY g.GENERATION;- 이번에는 CTE에서 각 재귀 개체 별로 SELECT를 해야 한다. 재귀 부분은 위와 같음
- 최종 SELECT 문에서 CTE에서 구한 개체와 ECOLI_DATA 개체를 LEFT JOIN 한 후, 자식이 없는 객체들을 필터링 한다. 일반 JOIN을 하게 되는 경우, PARENT_ID가 NULL이면 포함되지 않으므로 LEFT JOIN을 해야 한다!
- g는 자식 세대, e는 부모 세대를 의미 한다. 따라서 e.PARENT_ID IS NULL 조건이 자식이 없는 개체 필터링 조건이 된다.
- GROUP BY 를 이용해 각 세대별로 카운트 한다.
회고
나름 SQL 만져봤는데, 생각보다 어려워서 놀랐다.
특히 나는 서브쿼리를 좋아했는데...계속 JOIN에 익숙해지려 노력했다.
재귀는 처음 만져보는데 굉장히 어렵다. 매우매우 어렵다......
'코딩테스트' 카테고리의 다른 글
| [MySQL] 프로그래머스 SQL 고득점 Kit - GROUP BY (1) | 2025.02.21 |
|---|---|
| [MySQL] 프로그래머스 SQL 고득점 Kit - SUM, MAX, MIN (0) | 2025.02.21 |
| [Python] 백준 코테 연습 - DP (2) (0) | 2025.02.13 |
| [Python] 백준 코테 연습 - DP (1) (0) | 2025.02.05 |
| [Python] 백준 코테 연습 - DFS (0) | 2025.01.30 |