06. 아이템 기반 최근접 이웃 협업 필터링 실습
일반적으로 추천 정확도가 더 뛰어난 아이템 기반의 협업 필터링을 구현한다.
협업 필터링 추천을 위한 사용자-영화 평점 행렬 데이터 세트를 가져온다.
MovieLens Latest Datasets | GroupLens
MovieLens Latest Datasets
These datasets will change over time, and are not appropriate for reporting research results. We will keep the download links stable for automated downloads. We will not archive or make available p…
grouplens.org
데이터 가공 및 변환


협업 필터링은 ratings.csv 데이터 세트와 같이 사용자와 아이템 간의 평점에 기반해 추천하는 시스템이다.
먼저 로우 레밸 형태의 원본 데이터 세트를 사용자를 로우(행)으로, 영화를 칼럼(열)으로 구성한 데이터 세트로 변경한다.
ratings = ratings[['userId', 'movieId', 'rating']]
ratings_matrix = ratings.pivot_table('rating', index='userId', columns='movieId')
ratings_matrix.head(3)
pivot_table() 함수를 이용하면 쉽게 변경할 수 있다.
위와 같이 인자를 설정하면 로우 레밸은 userId, 칼럼은 movieId 칼럼의 값으로 이름이 바뀌고, rating 칼럼의 값이 데이터로 할당된다.
여기서 사용자가 평점을 매기지 않은 데이터는 NaN으로 할당되었는데, 최소 평점이 0.5이므로 NaN은 모두 0으로 변환한다.
또한 가독성을 위해 칼럼명을 movie가 아닌 movies 데이터 세트에 존재하는 영화명 tite로 변경한다.
# title 컬럼을 얻기 이해 movies 와 조인 수행
rating_movies = pd.merge(ratings, movies, on='movieId')
# columns='title' 로 title 컬럼으로 pivot 수행.
ratings_matrix = rating_movies.pivot_table('rating', index='userId', columns='title')
# NaN 값을 모두 0 으로 변환
ratings_matrix = ratings_matrix.fillna(0)
ratings_matrix.head(3)
영화 간 유사도 산출
영화 간의 유사도는 코사인 유사도를 기반으로 하고, cosine_similarity()를 이용해 측정한다.
cosine_similarity() 함수는 행을 기준으로 다른 행과 비교한다.
다만 우리는 영화(아이템) 간의 유사도를 비교해야 하므로 현재 ratings_matrix 데이터의 전치 행렬에 메소드를 적용해야 한다.
이를 위해 판다스의 transpose() 함수를 이용하자.
ratings_matrix_T = ratings_matrix.transpose()
ratings_matrix_T.head(3)
전치 행렬 데이터 세트의 cosine_similarity()를 적용하고 반환된 넘파이 행렬에 영화명을 매핑해 DataFrame으로 변환한다.
from sklearn.metrics.pairwise import cosine_similarity
item_sim = cosine_similarity(ratings_matrix_T, ratings_matrix_T)
# cosine_similarity() 로 반환된 넘파이 행렬을 영화명을 매핑하여 DataFrame으로 변환
item_sim_df = pd.DataFrame(data=item_sim, index=ratings_matrix.columns,
columns=ratings_matrix.columns)
print(item_sim_df.shape)
item_sim_df.head(3)
이 dataFrame을 이용해 영화 '인셉션'과 유사도가 높은 상위 5개(자신 제외)의 영화를 추출해보자.
item_sim_df["Inception (2010)"].sort_values(ascending=False)[1:6]title
Dark Knight, The (2008) 0.727263
Inglourious Basterds (2009) 0.646103
Shutter Island (2010) 0.617736
Dark Knight Rises, The (2012) 0.617504
Fight Club (1999) 0.615417
Name: Inception (2010), dtype: float64
아이템 기반 최근접 이웃 협업 필터링으로 개인화된 영화 추천
앞서 추출한 것과 같이 영화를 추천할 수 있지만, 이는 개인적인 취향을 반영하지 않고 영화 간 유사도만을 가지고 추천하였다.
개인화된 영화 추천을 하기 위해서는 개인이 아직 관람하지 않은 영화를 추천해야 한다.
즉, 아직 관람하지 않은 영화에 대해 아이템 유사도와 기존에 관람한 영화의 평점 데이터를 기반으로 새롭게 모든 영화의 예측 평점을 계산한 후 높은 예측 평점을 가진 영화를 추천한다.
개인화된 예측 평점은 다음 식으로 구할 수 있다.

여기서 N 값은 최근접 이웃 범위 계수를 의미한다.
이제 사용자별로 최적화된 평점 스코어를 예측하는 함수를 만든다.
만약 N의 범위에 제약을 두지 않으면 사용자별 예측 영화 평점 R은 모든 영화에 대한 예측 평점을 구하게 된다.
def predict_rating(ratings_arr, item_sim_arr ):
ratings_pred = ratings_arr.dot(item_sim_arr)/ np.array([np.abs(item_sim_arr).sum(axis=1)])
return ratings_pred
ratings_pred = predict_rating(ratings_matrix.values , item_sim_df.values)
ratings_pred_matrix = pd.DataFrame(data=ratings_pred, index= ratings_matrix.index,
columns = ratings_matrix.columns)
ratings_pred_matrix.head(3)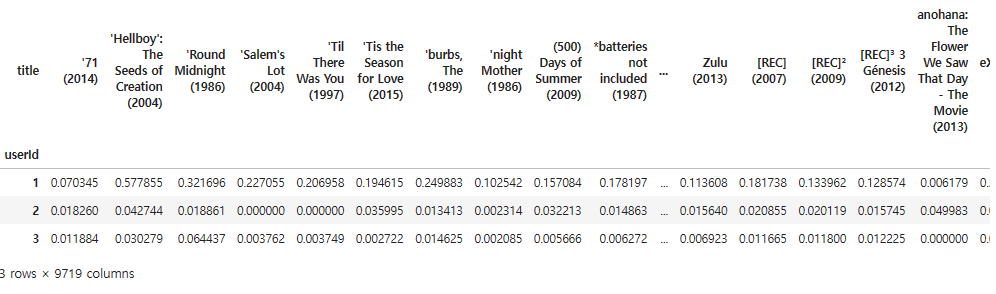
예측 평점이 사용자별 영화의 실제 평점과 영화의 코사인 유사도를 내적(dot)한 값이므로 기존에 0에 해당했던 영화 평점에도 값이 부여될 수 있다.
이렇게 되면 예측 평점이 실제 평점에 비해 작을 수 있다.
따라서 MSE를 이용해 예측 평가 지표를 측정하면 값이 크게 나올 수 있다.
MSE는 기존에 평점이 부여된 데이터에 대해서만 오차 정도를 측정한다.
from sklearn.metrics import mean_squared_error
# 사용자가 평점을 부여한 영화에 대해서만 예측 성능 평가 MSE 를 구함.
def get_mse(pred, actual):
# Ignore nonzero terms.
pred = pred[actual.nonzero()].flatten()
actual = actual[actual.nonzero()].flatten()
return mean_squared_error(pred, actual)
print('아이템 기반 모든 인접 이웃 MSE: ', get_mse(ratings_pred, ratings_matrix.values ))아이템 기반 모든 인접 이웃 MSE: 9.895354759094706MSE를 감소시켜야 한다.
MSE 감소를 위해 특정 영화와 가장 비슷한 유사도를 가지는영화에 대해서만 유사도 벡터를 적용한다.
n 인자를 받아 Top-N 유사도를 가지는 영화 유사도 벡터만 예측값을 계산하는 데 적용한다.
def predict_rating_topsim(ratings_arr, item_sim_arr, n=20):
# 사용자-아이템 평점 행렬 크기만큼 0으로 채운 예측 행렬 초기화
pred = np.zeros(ratings_arr.shape)
# 사용자-아이템 평점 행렬의 열 크기만큼 Loop 수행.
for col in range(ratings_arr.shape[1]):
# 유사도 행렬에서 유사도가 큰 순으로 n개 데이터 행렬의 index 반환
top_n_items = [np.argsort(item_sim_arr[:, col])[:-n-1:-1]]
# 개인화된 예측 평점을 계산
for row in range(ratings_arr.shape[0]):
pred[row, col] = item_sim_arr[col, :][top_n_items].dot(ratings_arr[row, :][top_n_items].T)
pred[row, col] /= np.sum(np.abs(item_sim_arr[col, :][top_n_items]))
return pred위 함수는 행, 열 별로 for 루프를 반복하며 Top-N 유사도 벡터를 계산하므로 데이터 세트가 커질수록 수행시간이 매우 커진다.(이 데이터 세트는 10만개인데 그렇게 오래 걸리지는 않았다..2~3분?)
ratings_pred = predict_rating_topsim(ratings_matrix.values , item_sim_df.values, n=20)
print('아이템 기반 인접 TOP-20 이웃 MSE: ', get_mse(ratings_pred, ratings_matrix.values ))
# 계산된 예측 평점 데이터는 DataFrame으로 재생성
ratings_pred_matrix = pd.DataFrame(data=ratings_pred, index= ratings_matrix.index,
columns = ratings_matrix.columns)아이템 기반 인접 TOP-20 이웃 MSE: 3.6949999176225483MSE가 많이 향상됐음을 확인할 수 있다.
이제 특정 사용자에 대해 영화를 추천한다.
먼저 9번 userId 사용자가 좋아하는 영화를 순서대로 나열한다.
user_rating_id = ratings_matrix.loc[9, :]
user_rating_id[ user_rating_id > 0].sort_values(ascending=False)[:10]title
Adaptation (2002) 5.0
Citizen Kane (1941) 5.0
Raiders of the Lost Ark (Indiana Jones and the Raiders of the Lost Ark) (1981) 5.0
Producers, The (1968) 5.0
Lord of the Rings: The Two Towers, The (2002) 5.0
Lord of the Rings: The Fellowship of the Ring, The (2001) 5.0
Back to the Future (1985) 5.0
Austin Powers in Goldmember (2002) 5.0
Minority Report (2002) 4.0
Witness (1985) 4.0전반적으로 흥행성이 좋은 영화에 높은 평점을 주고 있다.
이제 사용자가 이미 평점을 준 영화를 제외하고 추천할 수 있도록 평점을 주지 않은 영화를 리스트 객체로 반환하는 함수인 get_unseen_movies()를 생성한다.
def get_unseen_movies(ratings_matrix, userId):
# userId로 입력받은 사용자의 모든 영화정보 추출하여 Series로 반환함.
# 반환된 user_rating 은 영화명(title)을 index로 가지는 Series 객체임.
user_rating = ratings_matrix.loc[userId,:]
# user_rating이 0보다 크면 기존에 관람한 영화임. 대상 index를 추출하여 list 객체로 만듬
already_seen = user_rating[ user_rating > 0].index.tolist()
# 모든 영화명을 list 객체로 만듬.
movies_list = ratings_matrix.columns.tolist()
# list comprehension으로 already_seen에 해당하는 movie는 movies_list에서 제외함.
unseen_list = [ movie for movie in movies_list if movie not in already_seen]
return unseen_list
위 함수를 이용해 평점을 주지않은 대상 영화 정보와 predict_rating_topsim()에서 추출한 사용자별 아이템 유사도에 기반한 예측 평점 데이터 세트를 이용해 최종적으로 사용자에게 영화를 추천하는 함수를 만든다.
인자로 추천하려는 사용자 id, 추천 후보 영화 리스트, 추천 상위 영화 개수를 인자로 받는다.
def recomm_movie_by_userid(pred_df, userId, unseen_list, top_n=10):
# 예측 평점 DataFrame에서 사용자id index와 unseen_list로 들어온 영화명 컬럼을 추출하여
# 가장 예측 평점이 높은 순으로 정렬함.
recomm_movies = pred_df.loc[userId, unseen_list].sort_values(ascending=False)[:top_n]
return recomm_movies
# 사용자가 관람하지 않는 영화명 추출
unseen_list = get_unseen_movies(ratings_matrix, 9)
# 아이템 기반의 인접 이웃 협업 필터링으로 영화 추천
recomm_movies = recomm_movie_by_userid(ratings_pred_matrix, 9, unseen_list, top_n=10)
# 평점 데이타를 DataFrame으로 생성.
recomm_movies = pd.DataFrame(data=recomm_movies.values,index=recomm_movies.index,columns=['pred_score'])
recomm_movies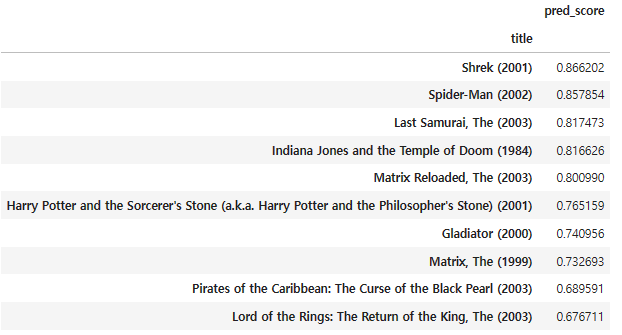
다양하고 높은 흥행성을 가진 작품이 추천됐다.
07. 행렬 분해를 이용한 잠재 요인 협업 필터링 실습
행렬 분해 잠재 요인 협업 필터링은 SVD나 NMF 등을 적용할 수 있는데, 일반적으로 사용자-아이템 평점 행렬에는 사용자가 평점을 매기지 않은 널 데이터가 많기 때문에 주로 SGD나 ALS 기반의 행렬 분해를 이용한다.
여기서는 SGD 기반의 행렬 분해를 구현하고 이를 기반으로 사용자에게 영화를 추천한다.
먼저 이전에 생성한 확률적 경사 하강법을 이용한 행렬 분해 예저의 get_rmse() 함수를 그대로 가져오고 행렬 분해 로직을 새로운 matrix_factorization() 함수로 정리한다.
인자로 R(원본 사용자-아이템 평점 행렬), K(잠재 요인의 차원 수), steps(SGD 반복 횟수), learning_rate(학습률), r_labda(규제 계수)가 있다.
import numpy as np
from sklearn.metrics import mean_squared_error
def get_rmse(R, P, Q, non_zeros):
error = 0
# 두개의 분해된 행렬 P와 Q.T의 내적 곱으로 예측 R 행렬 생성
full_pred_matrix = np.dot(P, Q.T)
# 실제 R 행렬에서 널이 아닌 값의 위치 인덱스 추출하여 실제 R 행렬과 예측 행렬의 RMSE 추출
x_non_zero_ind = [non_zero[0] for non_zero in non_zeros]
y_non_zero_ind = [non_zero[1] for non_zero in non_zeros]
R_non_zeros = R[x_non_zero_ind, y_non_zero_ind]
full_pred_matrix_non_zeros = full_pred_matrix[x_non_zero_ind, y_non_zero_ind]
mse = mean_squared_error(R_non_zeros, full_pred_matrix_non_zeros)
rmse = np.sqrt(mse)
return rmsedef matrix_factorization(R, K, steps=200, learning_rate=0.01, r_lambda = 0.01):
num_users, num_items = R.shape
# P와 Q 매트릭스의 크기를 지정하고 정규분포를 가진 랜덤한 값으로 입력합니다.
np.random.seed(1)
P = np.random.normal(scale=1./K, size=(num_users, K))
Q = np.random.normal(scale=1./K, size=(num_items, K))
# R > 0 인 행 위치, 열 위치, 값을 non_zeros 리스트 객체에 저장.
non_zeros = [ (i, j, R[i,j]) for i in range(num_users) for j in range(num_items) if R[i,j] > 0 ]
# SGD기법으로 P와 Q 매트릭스를 계속 업데이트.
for step in range(steps):
for i, j, r in non_zeros:
# 실제 값과 예측 값의 차이인 오류 값 구함
eij = r - np.dot(P[i, :], Q[j, :].T)
# Regularization을 반영한 SGD 업데이트 공식 적용
P[i,:] = P[i,:] + learning_rate*(eij * Q[j, :] - r_lambda*P[i,:])
Q[j,:] = Q[j,:] + learning_rate*(eij * P[i, :] - r_lambda*Q[j,:])
rmse = get_rmse(R, P, Q, non_zeros)
if (step % 10) == 0 :
print("### iteration step : ", step," rmse : ", rmse)
return P, Q
먼저 영화 평점 행렬 데이터를 새롭게 DataFrame으로 로딩한 뒤 다시 사용자-아이템 평점 행렬로 만든다.
import pandas as pd
import numpy as np
movies = pd.read_csv("C:/Users/jain5/Desktop/Euron/Data_Handling/movies.csv")
ratings = pd.read_csv("C:/Users/jain5/Desktop/Euron/Data_Handling/ratings.csv")
ratings = ratings[['userId', 'movieId', 'rating']]
ratings_matrix = ratings.pivot_table('rating', index='userId', columns='movieId')
# title 컬럼을 얻기 이해 movies 와 조인 수행
rating_movies = pd.merge(ratings, movies, on='movieId')
# columns='title' 로 title 컬럼으로 pivot 수행.
ratings_matrix = rating_movies.pivot_table('rating', index='userId', columns='title')
그 후 다시 만들어진 상ㅇ자-아이템 평점 행렬을 matrix_factorization() 함수를 이용해 행렬 분해한다.
P, Q = matrix_factorization(ratings_matrix.values, K=50, steps=200, learning_rate=0.01, r_lambda = 0.01)
pred_matrix = np.dot(P, Q.T)
예측 사용자-아이템 평점 행렬을 영화 타이틀 칼럼명으로 가지도록 DataFrame을 변경한다.
ratings_pred_matrix = pd.DataFrame(data=pred_matrix, index= ratings_matrix.index,
columns = ratings_matrix.columns)
ratings_pred_matrix.head(3)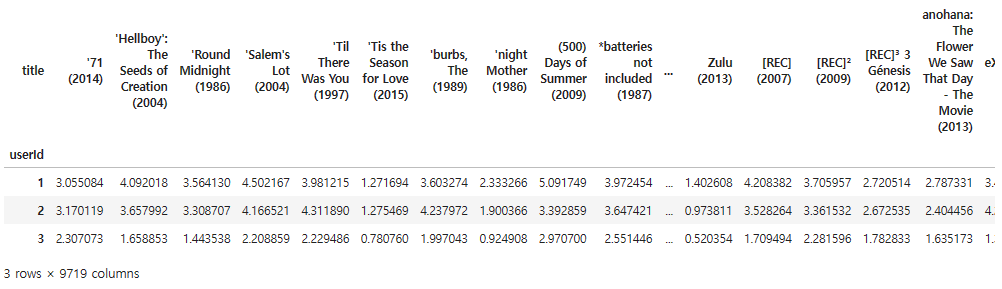
이렇게 만들어진 예측 사용자-아이템 평점 행렬 정보를 이용해 개인화된 영화 추천을 한다.
이전 절에서 만든 함수를 다시 이용해 추천 영화를 추출한다.
def get_unseen_movies(ratings_matrix, userId):
# userId로 입력받은 사용자의 모든 영화정보 추출하여 Series로 반환함.
# 반환된 user_rating 은 영화명(title)을 index로 가지는 Series 객체임.
user_rating = ratings_matrix.loc[userId,:]
# user_rating이 0보다 크면 기존에 관람한 영화임. 대상 index를 추출하여 list 객체로 만듬
already_seen = user_rating[ user_rating > 0].index.tolist()
# 모든 영화명을 list 객체로 만듬.
movies_list = ratings_matrix.columns.tolist()
# list comprehension으로 already_seen에 해당하는 movie는 movies_list에서 제외함.
unseen_list = [ movie for movie in movies_list if movie not in already_seen]
return unseen_list
def recomm_movie_by_userid(pred_df, userId, unseen_list, top_n=10):
# 예측 평점 DataFrame에서 사용자id index와 unseen_list로 들어온 영화명 컬럼을 추출하여
# 가장 예측 평점이 높은 순으로 정렬함.
recomm_movies = pred_df.loc[userId, unseen_list].sort_values(ascending=False)[:top_n]
return recomm_movies# 사용자가 관람하지 않는 영화명 추출
unseen_list = get_unseen_movies(ratings_matrix, 9)
# 아이템 기반의 인접 이웃 협업 필터링으로 영화 추천
recomm_movies = recomm_movie_by_userid(ratings_pred_matrix, 9, unseen_list, top_n=10)
# 평점 데이타를 DataFrame으로 생성.
recomm_movies = pd.DataFrame(data=recomm_movies.values,index=recomm_movies.index,columns=['pred_score'])
recomm_movies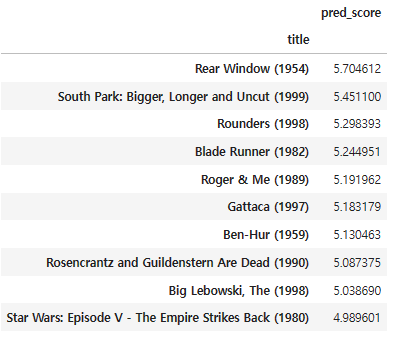
앞 절과는 약간 다른 결과가 나왔다.
약간 스릴러, 무거운 주제를 주로 다루는 영화들이 추천된 듯 하다.
# 회고
와 Euron 공부 끝이다! 이 복습과제를 끝으로 하고 이제 프로젝트 시작이다~!
이번 주제에 내가 낸 건 안됐지만 내가 좋아하는 다른 분야의 주제 팀에 들어갔다.
독서와 추천 시스템을 메인으로 하는 프로젝트이다. 끝까지 완성하고, 무엇보다 시각적으로 좀 예쁘게 결과물을 만들고 싶다.
배포를 해야하는데 가능할까? 해보고싶당ㅎ
'Euron > 정리' 카테고리의 다른 글
| [Week18] 09. 추천 시스템 - 실습 (0) | 2024.01.05 |
|---|---|
| [Week17] 09. 추천 시스템 (1) | 2023.12.30 |
| [Week16] 08. 텍스트 분석 - 실습(2) (0) | 2023.12.29 |
| [Week16] 08. 텍스트 분석 - 실습 (2) | 2023.12.22 |
| [Week12] Popular Unsupervised Clustering Algorithms (0) | 2023.12.18 |



