전에 만든 코드 리팩토링하고~
멘토링을 진행하며 보이스 추천 기능을 위한 데이터 확보를 위해 댓글(보이스) 추천 기능이 있으면 좋을 것 같다고 하셨다.
그것까지 수정하기.
# 리팩토링
class Mp3Upload(APIView):
# 댓글 전체 조회
def post(self, request, post_pk, format=None):
comments = Comment.objects.filter(post_id=post_pk).order_by('created_at') # 게시글 댓글 가져오고 오래된 순으로
comment_list = [{
"comment_id": comment.id,
"speed": comment.author_voice.speed,
"pitch": comment.author_voice.pitch,
"type": comment.author_voice.type,
"content": comment.content
} for comment in comments]
if len(comment_list)==0:
return Response({"RESULT": "변환할 댓글이 없습니다."}, status=400)
for i in range(len(comment_list)):
client = texttospeech.TextToSpeechClient()
synthesis_input = texttospeech.SynthesisInput(text=comment_list[i].get('content'))
voice = texttospeech.VoiceSelectionParams(
language_code="ko-KR", name=comment_list[i].get('type')
)
audio_config = texttospeech.AudioConfig(
audio_encoding=texttospeech.AudioEncoding.MP3,
pitch=comment_list[i].get('pitch'),
speaking_rate=comment_list[i].get('speed')
)
response = client.synthesize_speech(
input=synthesis_input,
voice=voice,
audio_config=audio_config
)
s3_client = boto3.client(
's3',
aws_access_key_id=ACCESS_KEY_ID,
aws_secret_access_key=SECRET_ACCESS_KEY
)
s3_client.put_object(Body=response.audio_content, Bucket=AWS_STORAGE_BUCKET_NAME, Key="mp3/"+str(post_pk)+"/"+str(i)+".mp3")
return Response({"RESULT": comment_list}, status=200)- 이 코드...PUT을 누를 때마다 전체 댓글을 다시 보이스 변환 후 s3에 올린다.
- 매번 그러면 너무 비효율적이니 추가된 댓글만 가져와서 변환할 것이다.
class Mp3Upload(APIView):
# 댓글 전체 조회
def post(self, request, post_pk, format=None):
comments = Comment.objects.filter(post_id=post_pk).order_by('created_at') # 게시글 댓글 가져오고 오래된 순으로
comment_list = [{
"comment_id": comment.id,
"speed": comment.author_voice.speed,
"pitch": comment.author_voice.pitch,
"type": comment.author_voice.type,
"content": comment.content
} for comment in comments]
if len(comment_list)==0:
return Response({"RESULT": "변환할 댓글이 없습니다."}, status=400)
s3_client = boto3.client(
's3',
aws_access_key_id=ACCESS_KEY_ID,
aws_secret_access_key=SECRET_ACCESS_KEY
)
s3_client.put_object(Bucket=AWS_STORAGE_BUCKET_NAME, Key="mp3/"+str(post_pk)+"/") # 오류...해결 -> 일단 무조건 폴더 생성
mp3_list = s3_client.list_objects(Bucket=AWS_STORAGE_BUCKET_NAME, Prefix="mp3/"+str(post_pk)+"/") # s3 버켓 가져와서
# 조회에서 시간걸림. redis 등으로 필요한 마지막 댓글 저장
content_list = mp3_list['Contents'] # contents 가져오기!
file_list = []
for content in content_list:
key = content['Key'] # Key값(파일명)만 뽑기
file_list.append(key)
for i in range(len(file_list)-1, len(comment_list)): # 폴더명도 포함되므로 -1부터 시작
client = texttospeech.TextToSpeechClient()
synthesis_input = texttospeech.SynthesisInput(text=comment_list[i].get('content'))
voice = texttospeech.VoiceSelectionParams(
language_code="ko-KR", name=comment_list[i].get('type')
)
audio_config = texttospeech.AudioConfig(
audio_encoding=texttospeech.AudioEncoding.MP3,
pitch=comment_list[i].get('pitch'),
speaking_rate=comment_list[i].get('speed')
)
response = client.synthesize_speech(
input=synthesis_input,
voice=voice,
audio_config=audio_config
)
s3_client = boto3.client(
's3',
aws_access_key_id=ACCESS_KEY_ID,
aws_secret_access_key=SECRET_ACCESS_KEY
)
s3_client.put_object(Body=response.audio_content, Bucket=AWS_STORAGE_BUCKET_NAME, Key="mp3/"+str(post_pk)+"/"+str(i)+".mp3")
return Response({"RESULT": comment_list, "반영된 댓글수": len(comment_list)-len(file_list)+1}, status=200)- 내 버킷 내 객체들을 가져와서 댓글 길이와 비교 후 새로 생긴 댓글만 넣기!
- 확실히 이전 코드는 5~10초 가량 소모됐는데 바꾼 후에는 바로 PUT함!
- 혹시 몰라서 이전 코드는 put으로 남겨두었다 ㅎㅎ 혹시라도 수정된 댓글을 반영하고 싶다고 하면 해줘야지.
# 좋아요 기능 추가하기
이번에는 새롭게 배운 issue도 사용해서 ㅎㅎㅎ
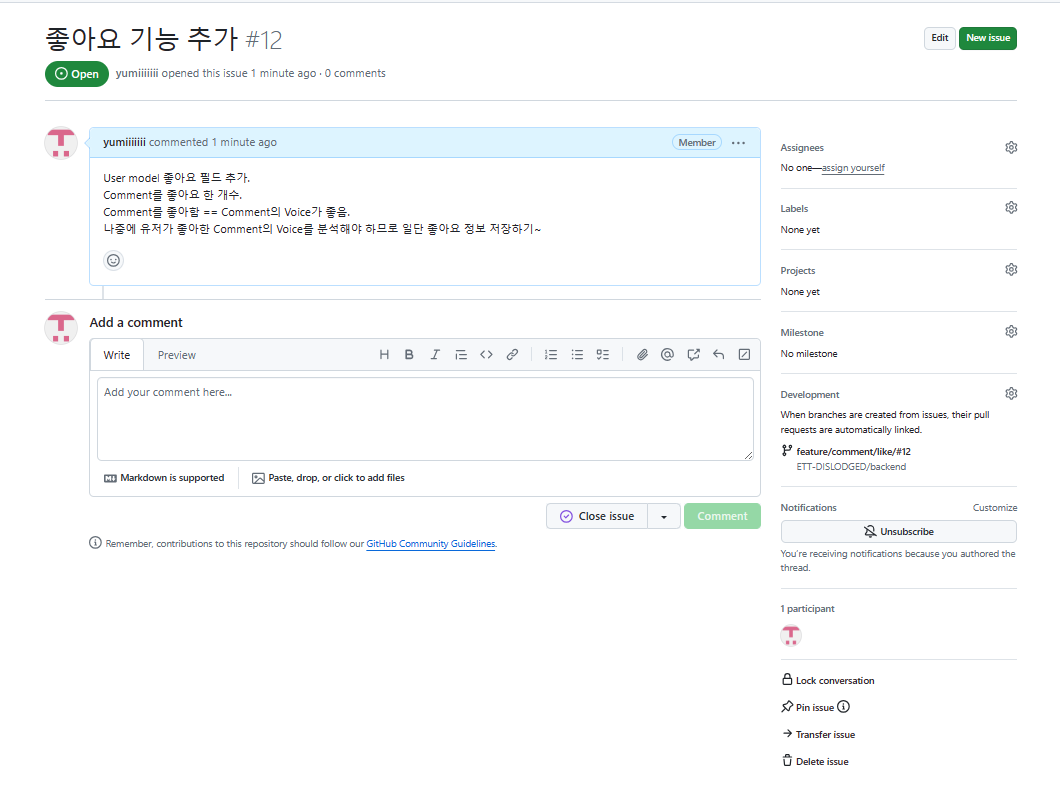
일단 모델을 만들어야 한다.
단순히 좋아요 갯수가 아닌 좋아요한 유저의 정보를 가져올 수 있어야 한다.
# models.py
class Comment(models.Model):
id = models.UUIDField(primary_key=True, default=uuid.uuid4, editable=False)
post=models.ForeignKey(Post, on_delete=models.CASCADE, related_name='comments')
author = models.ForeignKey(User, on_delete=models.CASCADE)
author_voice = models.ForeignKey(Voice_Info, on_delete=models.CASCADE, null=True) # 댓글 작성자의 Voice_Info
content = models.TextField()
created_at = models.DateTimeField(auto_now_add=True)
updated_at = models.DateTimeField(auto_now=True)
like=models.ManyToManyField(User, related_name='comment_like', blank=True)
def __str__(self):
return f'[{self.id}]{self.post.title} :: {self.author}'- 댓글-유저의 좋아요 관계는 다대다이므로 ManyToManyField로 추가 했다.
makemigraions + migrate 하기~
# serializers.py
class CommentSerializer(serializers.ModelSerializer):
author_id = serializers.ReadOnlyField(source='author.id')
author_nickname = serializers.ReadOnlyField(source = 'author.nickname')
author_username = serializers.ReadOnlyField(source='author.username') # username (아이디)추가
voice_speed = serializers.ReadOnlyField(source='author_voice.speed') # 댓글 작성자 voice 정보들 가져오기. voice_info가 바뀌면 이것도 바뀐다.
voice_pitch = serializers.ReadOnlyField(source='author_voice.pitch')
voice_type = serializers.ReadOnlyField(source='author_voice.type')
is_liked = serializers.BooleanField(default=False)
class Meta:
model=Comment
fields=['id','author_id', 'author_nickname','author_username','voice_speed','voice_pitch','voice_type','post','content','created_at','updated_at', 'is_liked']- Serializer에는 유저가 Comment를 불러올 때 해당 댓글을 좋아요한 유저인지 판별하기 위한 is_liked 필드를 추가했다.
from collections import Counter
# 좋아요한 댓글 목록
class LikedListView(APIView, PaginationHandlerMixin):
serializer_class = CommentSerializer
permission_classes = [IsAuthenticated]
def get(self, request):
user = request.user
comments = Comment.objects.filter(like=user.id)
voice_speed = 0
voice_pitch = 0
arr=[] # comment voice type 최빈값 찾기 위한 임시 배열
comment_list=[]
for comment in comments:
comment_list.append({
"comment_id": comment.id,
"speed": comment.author_voice.speed,
"pitch": comment.author_voice.pitch,
"type": comment.author_voice.type,
"content": comment.content
})
voice_speed += comment.author_voice.speed
voice_pitch += comment.author_voice.pitch
arr.append(comment.author_voice.type)
comment.is_liked=True
if len(comments)>0:
serializer = self.serializer_class(comments, many=True)
return Response({'message': '좋아요한 댓글 목록', 'data': serializer.data,
'speed_avg':voice_speed/len(comment_list), 'pitch_avg': voice_pitch/len(comment_list),
'type_avg':Counter(arr).most_common(1)[0][0]}, status=HTTP_200_OK)
else:
serializer = self.serializer_class(comments, many=True)
return Response({'message': '좋아요한 댓글 목록', 'data': serializer.data}, status=HTTP_200_OK)- Method는 POST와 DELETE만 필요하다.
- post요청이 들어오면 해당 pk의 댓글 객체를 가져온 후 like 필드에 유저를 추가한다.
- delete는 post와 반대로!
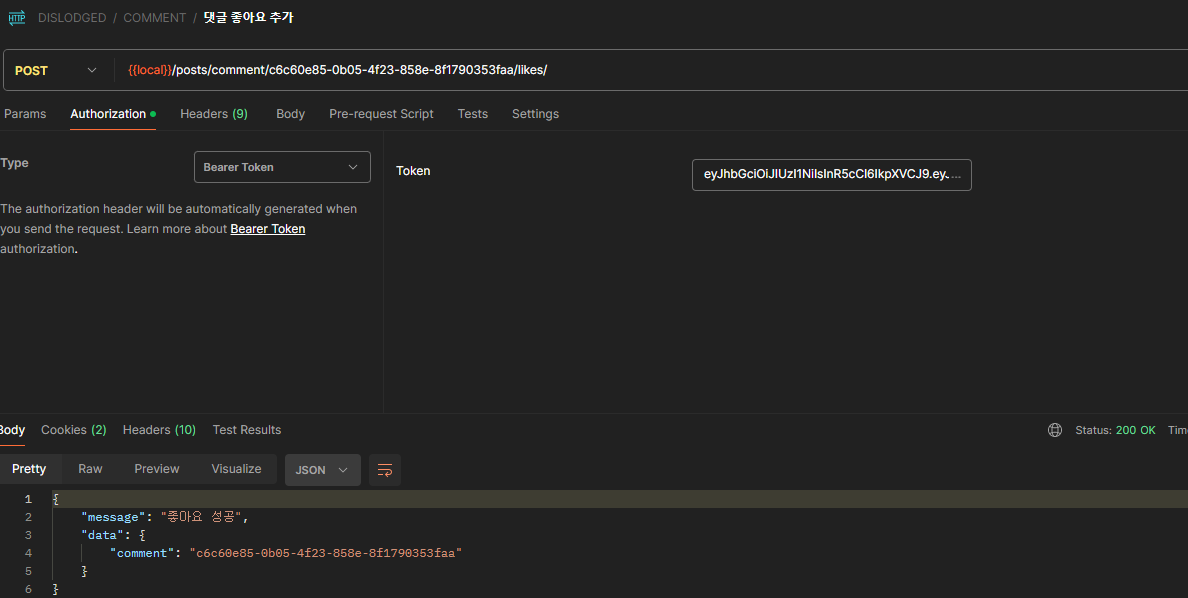
새롭게 좋아요 API도 만들었다.
이제 기존의 함수를 수정해서 comment를 불러올때 유저가 좋아요를 했는지 확인할 것이다.
class CommentViewSet(viewsets.ModelViewSet):
queryset=Comment.objects.all()
serializer_class=CommentSerializer
permission_classes = [IsAuthenticated, IsAuthor]
def list(self, request, *args, **kwargs):
comments = Comment.objects.all().order_by('-created_at')
comments = self.filter_queryset(comments)
if request.user:
for comment in comments:
if comment.like.filter(pk=request.user.id).exists():
comment.is_liked=True
serializer = self.serializer_class(comments, many=True)
return Response(serializer.data, status=status.HTTP_200_OK)
def retrieve(self, request, pk):
user = request.user
queryset = Comment.objects.all()
comment = get_object_or_404(queryset, pk=pk)
if comment.like.filter(pk=user.id).exists():
comment.is_liked=True
serializer = self.serializer_class(comment)
return Response(serializer.data, status=status.HTTP_200_OK)
def create(self, request, *args, **kwargs):
serializer = self.serializer_class(data = request.data, partial=True)
if serializer.is_valid():
serializer.is_liked=True
serializer.save(author=self.request.user, author_voice=self.request.user.user_voice)
return Response(serializer.data)- comment 함수...수정안할 줄 알고 심플한 ModelViewSet을 사용했다...🥲
- ModelViesSet에서 기본적으로 제공하는 6가지의 함수를 오버라이딩 해서 함수를 수정했다.
- 또한 기존의 create() 함수도 partial=True를 추가하며 is_liked는 건드리지 않아도 되도록! 수정했다.(오류로 뚜드려 맞고 추가함...)
# 기본 제공 함수
class ModelViewSet(mixins.CreateModelMixin,
mixins.RetrieveModelMixin,
mixins.UpdateModelMixin,
mixins.DestroyModelMixin,
mixins.ListModelMixin,
GenericViewSet):
"""
A viewset that provides default `create()`, `retrieve()`, `update()`,
`partial_update()`, `destroy()` and `list()` actions.
"""
pass- comment를 불러와서 comment모델의 like 필드에 유저가 존재한다면 is_liked 필드를 True로 바꾼 후 return해준다.
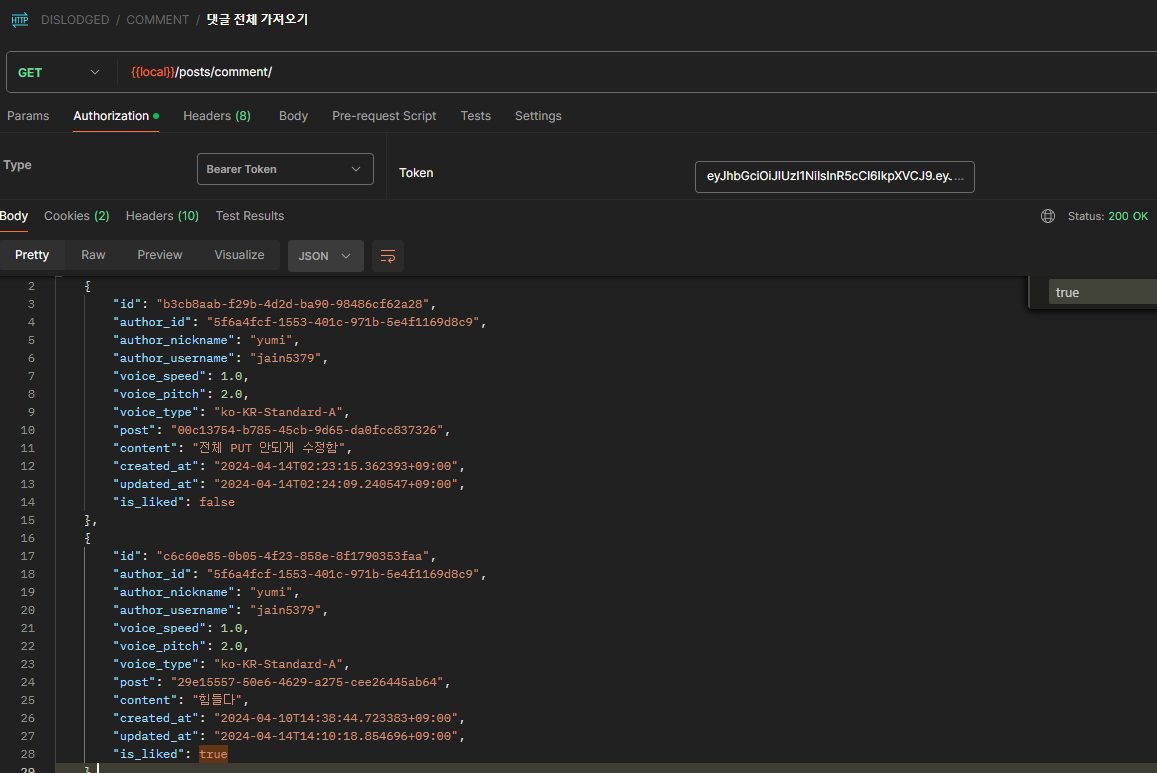
하지만 끝이 아니다. 이건 사실 부가적인 것임.
유저에게 보이스 추천을 하기 위해서는, 좋아요한 댓글들의 정보(특히 보이스 정보)를 가져올 수 있어야 한다!
from collections import Counter
# 좋아요한 댓글 목록
class LikedListView(APIView, PaginationHandlerMixin):
serializer_class = CommentSerializer
permission_classes = [IsAuthenticated]
def get(self, request):
user = request.user
comments = Comment.objects.filter(like=user.id)
voice_speed = 0
voice_pitch = 0
arr=[] # comment voice type 최빈값 찾기 위한 임시 배열
comment_list=[]
for comment in comments:
comment_list.append({
"comment_id": comment.id,
"speed": comment.author_voice.speed,
"pitch": comment.author_voice.pitch,
"type": comment.author_voice.type,
"content": comment.content
})
voice_speed += comment.author_voice.speed
voice_pitch += comment.author_voice.pitch
arr.append(comment.author_voice.type)
comment.is_liked=True
if len(comments)>0:
serializer = self.serializer_class(comments, many=True)
return Response({'message': '좋아요한 댓글 목록', 'data': serializer.data,
'speed_avg':voice_speed/len(comment_list), 'pitch_avg': voice_pitch/len(comment_list),
'type_avg':Counter(arr).most_common(1)[0][0]}, status=HTTP_200_OK)
else:
serializer = self.serializer_class(comments, many=True)
return Response({'message': '좋아요한 댓글 목록', 'data': serializer.data}, status=HTTP_200_OK)- get()으로 좋아요한 comment list 가져오기!
- voice 분석을 위해 리스트에 보이스 정보를 따로 담아주었다. 동시에 is_liked도 True로 바꾸기.
- 불러온 comment voice 정보들을 적당히 활용하여 평균낸 뒤 반환한다.
- 또한 만약 comment가 없다면 오류를 일으키지 않게 조건문 달아주기~

# bash (일부 삭제)
{
"message": "좋아요한 댓글 목록",
"data": [
{
"id": "8c3016af-9f89-403c-b3de-f6a2754c0c6a",
"author_id": "5f6a4fcf-1553-401c-971b-5e4f1169d8c9",
"author_nickname": "yumi",
"author_username": "jain5379",
"voice_speed": 1,
"voice_pitch": 2,
"voice_type": "ko-KR-Standard-A",
"post": "00c13754-b785-45cb-9d65-da0fcc837326",
"content": "같은 댓글 작성자인데 스피드를 바꾸면?",
"created_at": "2024-04-09T22:52:56.076028+09:00",
"updated_at": "2024-04-14T14:51:20.400188+09:00",
"is_liked": true
},
{
"id": "5f9cd582-8666-48ab-ae83-d2b19015f675",
"author_id": "5f6a4fcf-1553-401c-971b-5e4f1169d8c9",
"author_nickname": "yumi",
"author_username": "jain5379",
"voice_speed": 1,
"voice_pitch": 2,
"voice_type": "ko-KR-Standard-A",
"post": "00c13754-b785-45cb-9d65-da0fcc837326",
"content": "댓글입니다22",
"created_at": "2024-04-09T22:52:12.645413+09:00",
"updated_at": "2024-04-14T14:51:25.960373+09:00",
"is_liked": true
}
],
"speed 평균": 1,
"pitch 평균": 2,
"type 평균": "ko-KR-Standard-A"
}
# 오류 해결
이전 s3 코드에 오류가 있었다.
만약 이전에 댓글이 없어서 처음 s3에 업로드를 한다면, s3의 Contents를 가져올 수 없어 오류가 난다!
또한 post의 id를 이용해서 s3 객체를 가져오는데, mp3파일 뿐만 아니라 폴더도 함께 가져와서 음성 파일 개수+1개로 인식한다!
개수는 file_list -1로 혹은 pop()으로 해결해주었다.
s3 객체는 Contents를 가져오기 전에 미리 폴더를 만드는 방법으로 해결!
class Mp3Upload(APIView):
# 댓글 전체 조회
def post(self, request, post_pk, format=None):
comments = Comment.objects.filter(post_id=post_pk).order_by('created_at') # 게시글 댓글 가져오고 오래된 순으로
comment_list = [{
"comment_id": comment.id,
"speed": comment.author_voice.speed,
"pitch": comment.author_voice.pitch,
"type": comment.author_voice.type,
"content": comment.content
} for comment in comments]
if len(comment_list)==0:
return Response({"RESULT": "변환할 댓글이 없습니다."}, status=400)
s3_client = boto3.client(
's3',
aws_access_key_id=ACCESS_KEY_ID,
aws_secret_access_key=SECRET_ACCESS_KEY
)
s3_client.put_object(Bucket=AWS_STORAGE_BUCKET_NAME, Key="mp3/"+str(post_pk)+"/") # 오류...해결 -> 일단 무조건 폴더 생성
mp3_list = s3_client.list_objects(Bucket=AWS_STORAGE_BUCKET_NAME, Prefix="mp3/"+str(post_pk)+"/") # s3 버켓 가져와서
content_list = mp3_list['Contents'] # contents 가져오기!
file_list = []
for content in content_list:
key = content['Key'] # Key값(파일명)만 뽑기
file_list.append(key)
for i in range(len(file_list)-1, len(comment_list)): # 폴더명도 포함되므로 -1부터 시작
client = texttospeech.TextToSpeechClient()
synthesis_input = texttospeech.SynthesisInput(text=comment_list[i].get('content'))
voice = texttospeech.VoiceSelectionParams(
language_code="ko-KR", name=comment_list[i].get('type')
)
audio_config = texttospeech.AudioConfig(
audio_encoding=texttospeech.AudioEncoding.MP3,
pitch=comment_list[i].get('pitch'),
speaking_rate=comment_list[i].get('speed')
)
response = client.synthesize_speech(
input=synthesis_input,
voice=voice,
audio_config=audio_config
)
s3_client = boto3.client(
's3',
aws_access_key_id=ACCESS_KEY_ID,
aws_secret_access_key=SECRET_ACCESS_KEY
)
s3_client.put_object(Body=response.audio_content, Bucket=AWS_STORAGE_BUCKET_NAME, Key="mp3/"+str(post_pk)+"/"+str(i)+".mp3")
return Response({"RESULT": comment_list, "반영된 댓글수": len(comment_list)-len(file_list)+1}, status=200)
def get(self, request, post_pk, format=None):
comments = Comment.objects.filter(post_id=post_pk)
s3_client = boto3.client(
's3',
aws_access_key_id=ACCESS_KEY_ID,
aws_secret_access_key=SECRET_ACCESS_KEY
)
s3_client.put_object(Bucket=AWS_STORAGE_BUCKET_NAME, Key="mp3/"+str(post_pk)+"/") # 오류...해결 -> 일단 무조건 폴더 생성
mp3_list = s3_client.list_objects(Bucket=AWS_STORAGE_BUCKET_NAME, Prefix="mp3/"+str(post_pk)+"/") # s3 버켓 가져와서
content_list = mp3_list['Contents'] # contents 가져오기!
file_list = []
for content in content_list:
key = content['Key'] # Key값(파일명)만 뽑기
file_list.append(key)
file_list.pop() # file_list는 알파벳순이므로 폴더명은 빼주기
# print(file_list)
if len(comments)==0:
return Response({"RESULT": "댓글을 달아주세요!"}, status=400)
elif str(post_pk) not in ''.join(file_list): # 변환하지 않은 댓글이 있다면
return Response({"RESULT": "음성 변환을 먼저 해주세요!"}, status=400)
data = []
for i in range(len(comments)):
url = f"https://{AWS_STORAGE_BUCKET_NAME}.s3.ap-northeast-2.amazonaws.com/"+"mp3/"+str(post_pk)+"/"+str(i)+".mp3" # 이렇게 url 가져오기
data.append(url)
return Response({"RESULT": data}, status=200)
# 회고
아 너무 힘들다...........................
엄청 빠르게 시작했는데 왜 안끝나지.....
'졸업 프로젝트' 카테고리의 다른 글
| 수정 + 댓글 필터링 (1) | 2024.05.07 |
|---|---|
| mp3 파일 다루기 - S3 업로드&객체 가져오기 (2) (1) | 2024.04.10 |
| mp3 파일 다루기 - S3 업로드&객체 가져오기 (1) (0) | 2024.04.09 |
| 이미지 파일 다루기(AWS S3 이용) (0) | 2024.03.28 |
| Google Cloud TTS 이용하기 + 배포 오류 해결 (3) | 2024.03.18 |



