지난번에 하던거 이어서!
# 모든 댓글 변환&업로드
일단 한 게시글의 comment를 모두 가져오자.
class Mp3Upload(APIView):
# 댓글 전체 조회
def post(self, request, post_pk, format=None):
comments = Comment.objects.filter(post_id=post_pk)
comment_list = [{
"comment_id": comment.id,
"speed": comment.author_voice.speed,
"pitch": comment.author_voice.pitch,
"type": comment.author_voice.type,
"content": comment.content
} for comment in comments]
for i in comment_list:
print(i)
# s3에 업로드 코드
이렇게 나온다.
이제 comment_list를 돌면서 print가 아닌 각각 음성파일로 변환하기!
class Mp3Upload(APIView):
# 댓글 전체 조회
def post(self, request, post_pk, format=None):
comments = Comment.objects.filter(post_id=post_pk)
comment_list = [{
"comment_id": comment.id,
"speed": comment.author_voice.speed,
"pitch": comment.author_voice.pitch,
"type": comment.author_voice.type,
"content": comment.content
} for comment in comments]
print(comment_list)
for i in range(len(comment_list)):
client = texttospeech.TextToSpeechClient()
synthesis_input = texttospeech.SynthesisInput(text=comment_list[i].get('content'))
voice = texttospeech.VoiceSelectionParams(
language_code="ko-KR", name=comment_list[i].get('type')
)
audio_config = texttospeech.AudioConfig(
audio_encoding=texttospeech.AudioEncoding.MP3,
pitch=comment_list[i].get('pitch'),
speaking_rate=comment_list[i].get('speed')
)
response = client.synthesize_speech(
input=synthesis_input,
voice=voice,
audio_config=audio_config
)
s3_client = boto3.client(
's3',
aws_access_key_id=ACCESS_KEY_ID,
aws_secret_access_key=SECRET_ACCESS_KEY
)
s3_client.put_object(Body=response.audio_content, Bucket=AWS_STORAGE_BUCKET_NAME, Key="mp3/"+str(post_pk)+"/"+str(i)+".mp3")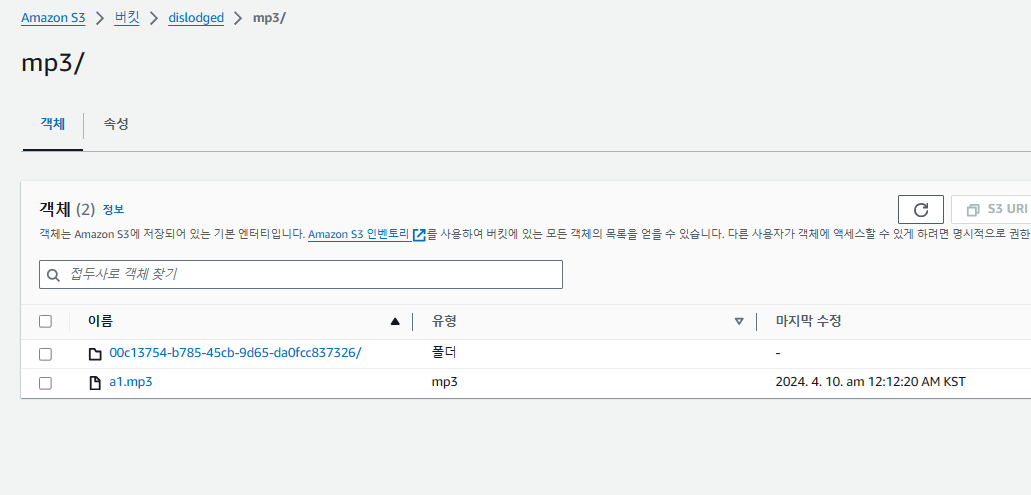
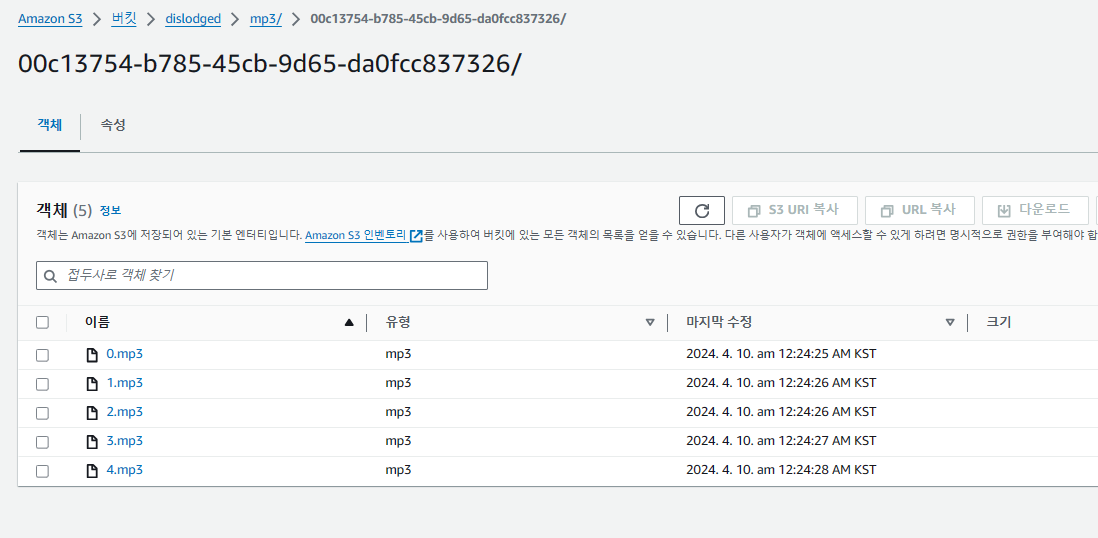
폴더 이름은 게시글 uuid, 생성된 voice들의 각 객체 이름은 그냥..순서대로 인덱스로 넣었다. uuid 넘 길어..
주의할 점은 Key 설정할 때 str로 다 변환해주어야 한다는 점?
# 변환된 S3 객체 모두 가져오기
class Mp3Upload(APIView):
def get(self, request, post_pk, format=None):
s3_client = boto3.client(
's3',
aws_access_key_id=ACCESS_KEY_ID,
aws_secret_access_key=SECRET_ACCESS_KEY
)
mp3_list = s3_client.list_objects(Bucket=AWS_STORAGE_BUCKET_NAME) # s3 버켓 가져와서
content_list = mp3_list['Contents'] # contents 가져오기!
comments = Comment.objects.filter(post_id=post_pk)
data = []
for i in range(len(comments)):
url = f"https://{AWS_STORAGE_BUCKET_NAME}.s3.ap-northeast-2.amazonaws.com/"+"mp3/"+str(post_pk)+"/"+str(i)+".mp3" # 이렇게 url 가져오기
data.append(url)
# url = f'https://{AWS_STORAGE_BUCKET_NAME}.s3.ap-northeast-2.amazonaws.com/mp3/a1.mp3' # 이렇게 url 가져오기
return Response({"RESULT": data}, status=200)
get할 때 Contents의 'Key'를 키 값으로 가지는 객체 중 post_pk가 들어가는..어쩌구 filter를 걸어서 가져오려 했는데 그냥 url의 이름을 아니까 직접 적어서 추가해준다 ㅎㅎ
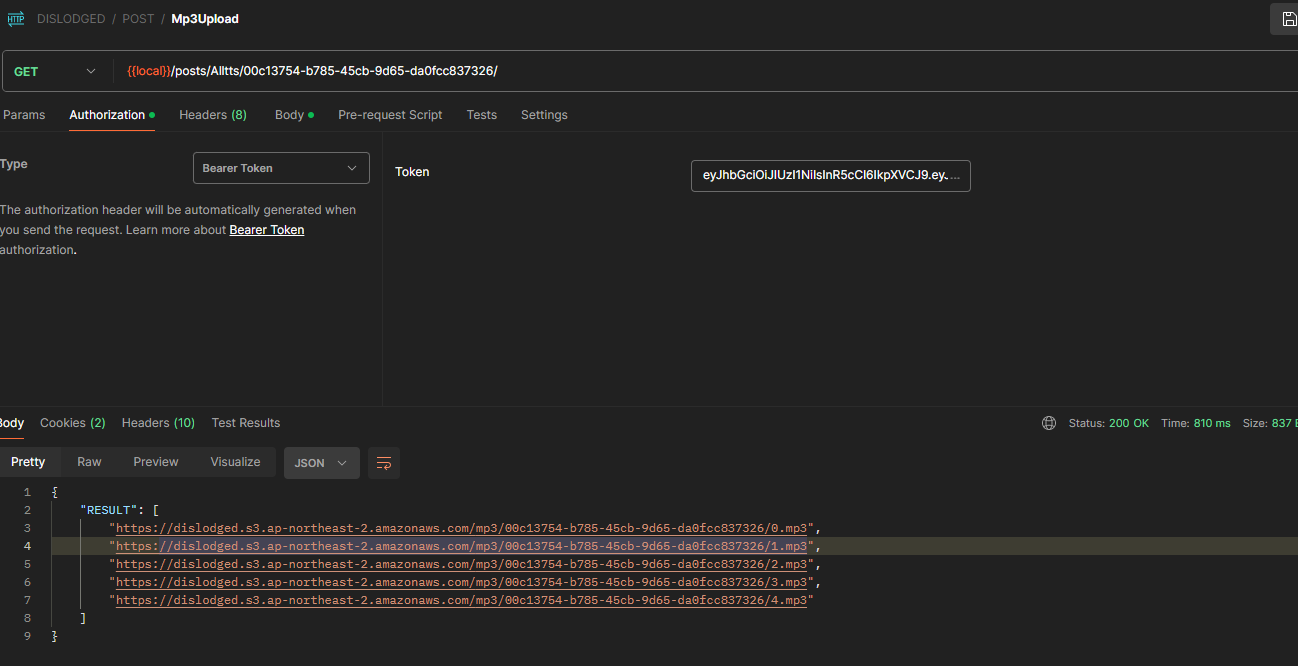
# 환경변수 설정 + 수정
# settings.py
BASE_DIR = os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
env = environ.Env(
DEBUG=(bool, False)
)
os.environ["GOOGLE_APPLICATION_CREDENTIALS"]=env('GOOGLE_APPLICATION_CREDENTIALS') # tts를 위한..경로 지정..local에서만 사용하기
ACCESS_KEY_ID = env('ACCESS_KEY_ID')
SECRET_ACCESS_KEY = env('SECRET_ACCESS_KEY')
AWS_REGION = 'ap-northeast-2'
AWS_STORAGE_BUCKET_NAME = 'dislodged'
AWS_S3_CUSTOM_DOMAIN = '%s.s3.%s.amazonaws.com' % (AWS_STORAGE_BUCKET_NAME, AWS_REGION)
DEFAULT_FILE_STORAGE = 'storages.backends.s3boto3.S3Boto3Storage'중요한 KEY같은 정보들은 git에 올라가지 않게 .env에 올려두고 사용한다!
class Mp3Upload(APIView):
def get(self, request, post_pk, format=None):
comments = Comment.objects.filter(post_id=post_pk)
s3_client = boto3.client(
's3',
aws_access_key_id=ACCESS_KEY_ID,
aws_secret_access_key=SECRET_ACCESS_KEY
)
mp3_list = s3_client.list_objects(Bucket=AWS_STORAGE_BUCKET_NAME) # s3 버켓 가져와서
content_list = mp3_list['Contents'] # contents 가져오기!
file_list = []
for content in content_list:
key = content['Key'] # Key값(파일명)만 뽑기
file_list.append(key)
if len(comments)==0:
return Response({"RESULT": "댓글을 달아주세요!"}, status=400)
elif str(post_pk) not in ''.join(file_list):
return Response({"RESULT": "음성 변환을 먼저 해주세요!"}, status=400)
data = []
for i in range(len(comments)):
url = f"https://{AWS_STORAGE_BUCKET_NAME}.s3.ap-northeast-2.amazonaws.com/"+"mp3/"+str(post_pk)+"/"+str(i)+".mp3" # 이렇게 url 가져오기
data.append(url)
return Response({"RESULT": data}, status=200)API문서를 정리하다 생각해보니 댓글을 달았지만 음성파일로 변환이 되지 않은 경우, 즉 POST를 미리 하지 않았다던가..
아니면 댓글이 없는 경우도 있을 것이다!
그런 경우는 따로 400 Return을 한다.
s3의 contents를 뽑고, 거기서 Key를 뽑아와서 post_pk의 폴더명으로 음성파일을 찾을 것이다.
근데 POST를 미리 하는..게 아니라 GET할 때마다 음성 파일 변환도 같이 할 수도..? 이건 나중에 수정해야지
class Mp3Upload(APIView):
# 댓글 전체 조회
def post(self, request, post_pk, format=None):
comments = Comment.objects.filter(post_id=post_pk).order_by('created_at') # 게시글 댓글 가져오고 오래된 순으로
comment_list = [{
"comment_id": comment.id,
"speed": comment.author_voice.speed,
"pitch": comment.author_voice.pitch,
"type": comment.author_voice.type,
"content": comment.content
} for comment in comments]
if len(comment_list)==0:
return Response({"RESULT": "변환할 댓글이 없습니다."}, status=400)post도 약간 수정~댓글도 오래된 순으로 변환하도록 정렬함
# 회고
힘들구만..
이제 API문서도 어느정도 정리했으니 일단 commit해야지.
이 음성을 합치거나 배경음악 처리하는 건 프론트랑 다시 상의해볼 예정.
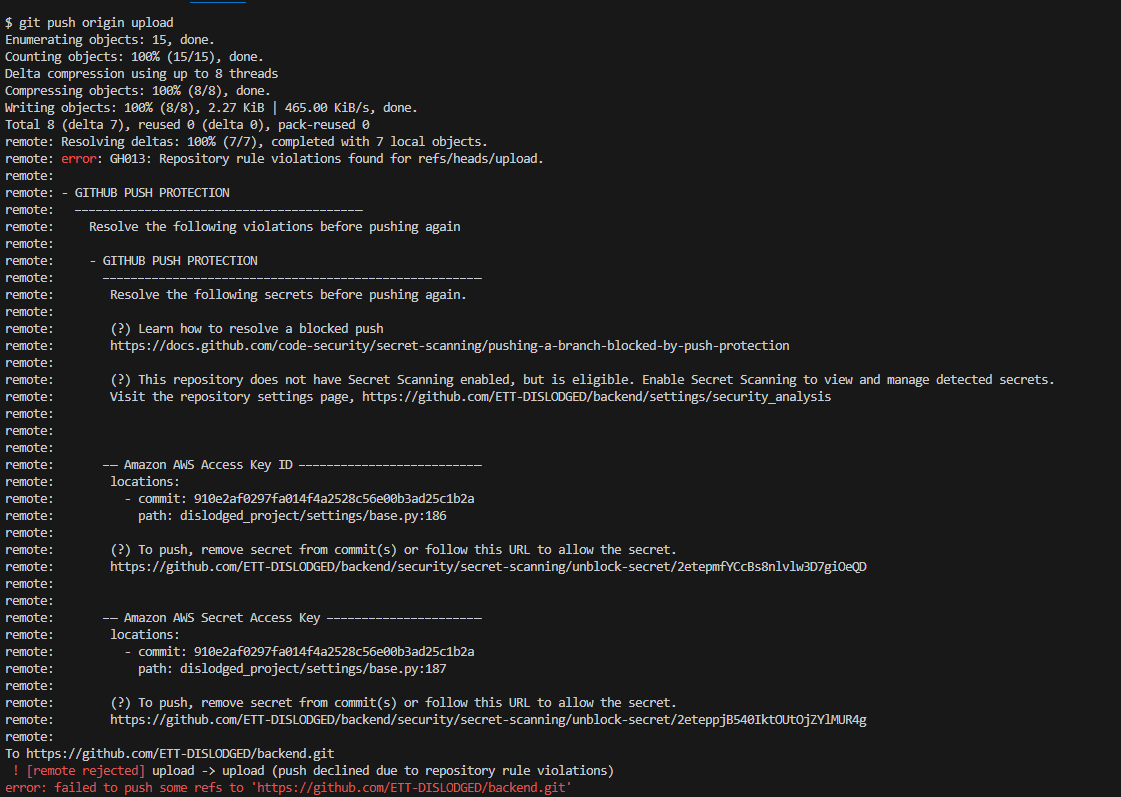
와 commit 할 때 깜빡하고 잠깐 적어둔 AWS Access Key를 지우지 않았는데 미리 경고해준다!
친절하구만..
다행이다 ㅎㅎㅎ
배포할때는..잊지 말자. git secret에도 변수 업로드 해주고..ㅎ
'졸업 프로젝트' 카테고리의 다른 글
| 수정 + 댓글 필터링 (1) | 2024.05.07 |
|---|---|
| mp3 파일 다루기 - S3 업로드&객체 가져오기 (3) + 좋아요 기능 (0) | 2024.04.16 |
| mp3 파일 다루기 - S3 업로드&객체 가져오기 (1) (0) | 2024.04.09 |
| 이미지 파일 다루기(AWS S3 이용) (0) | 2024.03.28 |
| Google Cloud TTS 이용하기 + 배포 오류 해결 (3) | 2024.03.18 |



