멘토분께서 비동기식 처리&빠른 DB 접근을 위해 Redis를 공부하라 하심. TTS API를 돌릴 때 꽤 시간이 걸려서..
할 수 있을까?
# 이론 정리
Redis란?
- redis란, 간단하게 말하면 그냥 DB이다. 키-밸류 형식으로 데이터를 저장할 수 있는 NoSQL(이것 말고도 다른 자료구조가 많지만 가장 많이 이용하는 것은 이런 dictionary형태)
- 또한 데이터를 메모리에 직접 저장, 즉 In-memory로 저장하므로 데이터 정렬 및 조회가 일반 DB보다 빠르다.
- 저장 공간 제약이 있어 주메모리로는 사용 X
- 데이터의 지속성을 보장하기 위해 두가지의 데이터 백업 방식을 같이 사용한다.
- RDB : 한 순간을 포착하여 메모리에 있는 내용을 DISK로 옮겨 담는 방식 -> 유실 가능성 O
- AOF : 데이터 변경 이벤트(CUD)가 발생하면 이를 모두 로그에 저장하는 방식 -> 유실 가능성 X, 단 RDB보다 속도가 느리고 파일 크기가 크다.
- 이외에도 싱글 스레드를 사용하여 dead lock 발생 X, Context switch 발생 X 등의 특징이 있음.
- 위와 같은 특징들로 인해 일부 데이터 저장 및 증감 연산, 분산 락 등 다양한 상황에서 redis로 효율적으로 관리 가능!
- 최신 버전 redis는 PUB/SUB 형태의 기능을 제공하여 메세지를 전달할 수 있다. 예를 들면 어떠한 기능을 처리했을때 알림을 보내는 것!
비동기 방식과 redis?
- 일단, 비동기 방식이란 무엇인가...
- 동기 방식은 요청이 들어오면 동시에 처리하는 것으로, 요청에 대한 처리가 즉시 나타난다. 설계가 간단하지만 결과가 나올때까지 아무것도 하지 못하므로 요청이 커지면 효율이 떨어진다.
- 비동기 방식은 반대로 요청한 결과를 동시에 처리하지 않는다. 동기 방식보다 복잡하고 결과가 나오는데 오래걸리지만 그 시간동안 다른 작업이 가능하다.
- 그렇다면 redis로 어떻게 비동기식 처리를 하는가...걍 DB인데?
- 라고 생각했는데 redis 자체가 작업을 처리하는 것은 아니고, 작업을 전달하는 역할을 맡는 것이다. 이를 Broker라 한다.
- Broker 종류는 여러개가 있다. Redis, Kafka, RabbitMQ 등...비교는 https://jungyu09.tistory.com/14
- Broker도 메시지 브로커(Redis, RabbitMQ)와 이벤트 브로커(Kafka)로 나뉜다... 대충 빠른 처리를 원하면 메시지 브로커, 서비스 이벤트를 저장하고 관리하며 느려도 데이터 손실이 없기를 바라면 이벤트 브로커 사용.
- 이제 Broker가 작업을 전달하면, 이것을 작업하는 것은 Worker라고 부른다.
Worker, Celery!
- 위에서 말했듯이 Worker는 Broker가 전달한 작업을 처리하는 역할이다.
- 즉, broker가 서비스에서 발생한 요청을 여러 workers들(큐 자료구조에 작업을 나누어 보내기) 처리하라고 보낸다.
- Celery는 Python 동시성 프로그래밍에서 사용하는 비동기식 작업 큐이다.
- 아래는 요약..

- 궁금해서 찾아봤는데 spring은 따로 설치는 안하고 @Async 어노테이션이랑 CompletableFuture클래스를 이용한다함.
이론을 정리하니까 조금 알것같다. 왜 db를 가지고 비동기식 처리를 하라는 것인가 했는데..작업 자체는 딴게 하는 거군아!
django에서는 celery랑 redis install하고 환경 설정하고~ 해주면 된다.
https://docs.celeryq.dev/en/latest/getting-started/first-steps-with-celery.html#first-steps
First Steps with Celery — Celery 5.4.0 documentation
This document describes the current stable version of Celery (5.4). For development docs, go here. First Steps with Celery Celery is a task queue with batteries included. It’s easy to use so that you can get started without learning the full complexities
docs.celeryq.dev
공식문서를 참고하면서 작업해주자
# local redis 이용하기
이전에 redis를 설치 했었다.
C:\Program Files\Redis로 들어가서 redis-cli를 키면 local redis server가 켜진다.

터미널을 꺼도 백그라운드에서 서버가 돌아가는 것 같다. 터미널 껐는데 celery가 돌아갔음
# local redis&celery 이용하기
이제 프로젝트에서 celery를 이용하여 기능을 구현할 것이다.
내가 이번 프로젝트에서 구현하려는 것은 어떠한 객체의 start_time field가 현재 시간을 지나면 end_type을 3으로 자동으로 update하는 기능이다.
먼저, Celery는 크게 두가지 작업으로 나눌 수 있다.
- Celery Worker : 오래 걸리는 작업을 app과 분리하여 비동기로 작업. 내 졸프가 여기에 해당한다.
- Celery Beat : 주기적으로 동작해야 하는 작업. 이번에 구현하려는 기능
이제 본격적으로 구현을 해본다.
필요한 라이브러리는 다음과 같다.
# Celery 설치
pip install celery # worker
pip install django-celery-beat # beat
pip install django-celery-results # celery 결과
# Redis python package 설치
pip install redis
settings.py에 설치한 라이브러리를 등록하고, redis의 주소를 입력한다.
INSTALLED_APPS = [
'django_celery_beat',
'django_celery_results',
]
CELERY_BROKER_URL = 'redis://127.0.0.1:6379/0' # Redis 서버 주소와 포트
CELERY_RESULT_BACKEND = 'redis://127.0.0.1:6379/0' # Redis 서버 주소와 포트
CELERY_ACCEPT_CONTENT = ['json']
CELERY_TASK_SERIALIZER = 'json'
CELERY_TASK_ALWAYS_EAGER = False
CELERY_TIMEZONE = TIME_ZONE # Celery Beats에서 사용할 Time Zone
CELERY_TASK_TRACK_STARTED = True.
celery와 관련된 주요 설정들은 {프로젝트 명}/celery.py 로 새로운 폴더를 만들고 안에서 설정해주었다.
app.conf.update(worker_pool='solo') 이 부분이 특히 windows환경에서 들어가야 한다.
다중 스레드 대신 단일스레드를 사용한다는 뜻이다. windows가 다중 스레드를 지원하지 않아 생기는 문제...
실제 배포 환경에서는 쓰지 말고, 로컬 환경이 window라면 꼭 넣어주기
from __future__ import absolute_import, unicode_literals
import os
from celery import Celery
from celery.schedules import crontab
os.environ.setdefault(
"DJANGO_SETTINGS_MODULE",
"config.settings",
)
app = Celery('config')
app.config_from_object('django.conf:settings', namespace='CELERY')
app.autodiscover_tasks()
app.conf.beat_schedule = { # 여기에 작성하는 것이 celery가 수행할 작업들이다.
'dataReset': { # 이건 다른사람 작업. 24시간에 한번씩 data를 reset하는 task
'task': 'user.tasks.dataReset',
'schedule': crontab(minute=0, hour=0),
},
"test-periodic-job": { # 내작업!
"task": "game.tasks.test_periodic_task",
'schedule': crontab(minute='*'), # 1분마다
}
}
app.conf.update(worker_pool='solo')
@app.task(bing=True)
def debug_task(self):
print(f'Request: {self.request!r}')
{프로젝트명}/__init__.py 에 아래와 같이 작성한다.
Django가 시작될 때 app이 구동되며 @shared_task 데코레이터를 사용할 수 있도록 한다.
from __future__ import absolute_import, unicode_literals
from .celery import app as celery_app
__all__ = ('celery_app',)
app안에 tasks.py 파일을 만들고 코드를 구현한다.
멍청한 celery는 경로가 복잡해지면 인식을 못한다....그냥 app바로 아래에 만들어주는게 좋다.
# game/tasks.py
from __future__ import absolute_import, unicode_literals
from django.utils import timezone
from celery import shared_task
from game.models import TbTournament
from datetime import timedelta
@shared_task
def test_periodic_task():
current_time = timezone.now()
# 9시간 후의 시간 계산
nine_hours_utc = current_time + timedelta(hours=9)
print(f"Current time (KST): {current_time}") # 디버깅을 위해 현재 시간을 출력
# start_time이 현재 시간을 지난 모든 레코드 중 end_type이 0인 것들 필터링
records = TbTournament.objects.filter(start_time__lte=nine_hours_utc, end_type=0)
# print(f"Number of records to update: {len(records)}")
for record in records:
record.end_type = 3
record.save()
print(f"Updated record id {record.id}: start_time was {record.start_time}")
return f"Updated tournament records."UTC 시간으로 현재 시간하고 비교가 어려워 그냥 9시간 후의 시간과start_time을 비교하기로 했다.
celery -A config beat -l info
celery -A config worker -l info
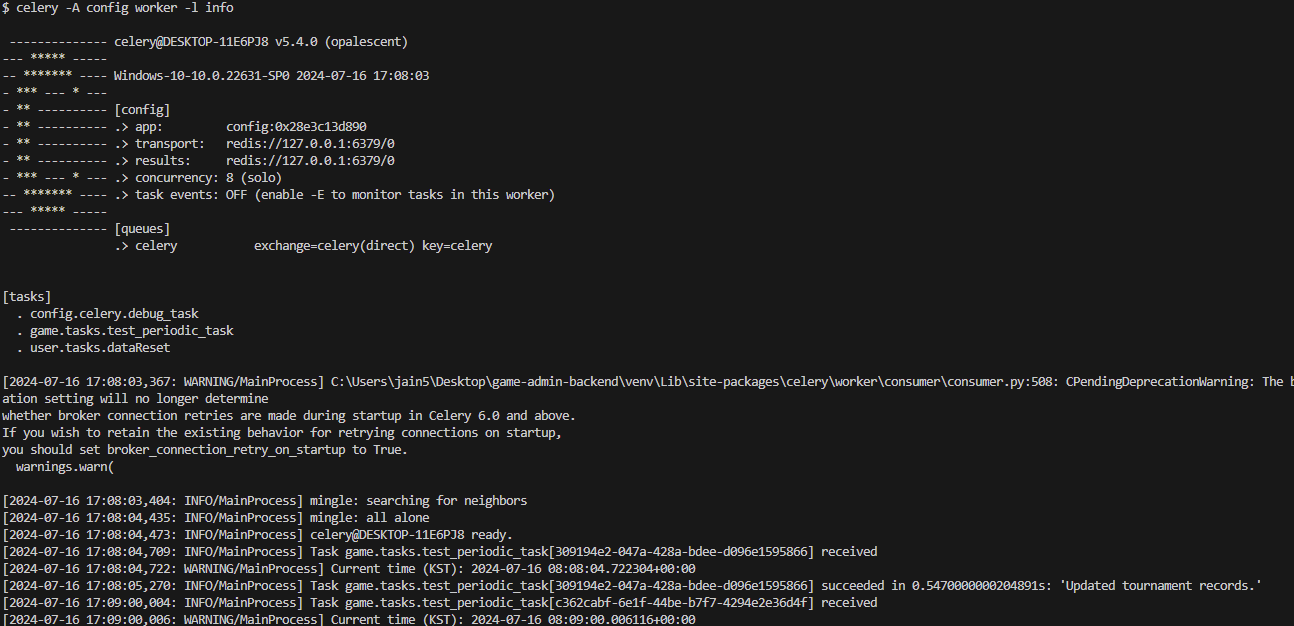
조건에 맞게 잘가져오고 수정도 잘된다!
배포는 docker에서 이미지를 만들어야 할텐데...그건 다음에!
# celery worker
주기적인 작업이 아닌 비동기 작업을 하는 법.
설정은 beat랑 똑같다.
# (app)/tasks.py
from celery import shared_task
@shared_task
def test_task(a: int, b: int):
print("test Celery task : ", a + b)
return a + btasks.py에 비동기식으로 하려는 작업을 작성한다.
# (app)/views.py
from django.http import HttpRequest
from rest_framework import views
from rest_framework.response import Response
from .tasks import test_task
from celery.result import AsyncResult
class Test(views.APIView):
def get(self, request: HttpRequest):
test_task(2,5)
return Response("Celery Task Running")views.py에서 자유롭게 비동기 함수를 사용하면 된다.
# 회고
내 첫 목표는 celery 배우기 였는데 회사에서 이렇게 빠르게 배워보는 날이 올 줄은 몰랐다.
물론 배포할 때 docker 설정도 배우고 배포 후에 잘 되는지 확인해야겠지만...
windows라 고생을 좀 하긴 했는데 어쨌든 끝
'django > 정리' 카테고리의 다른 글
| [Django] NHN Cloud 휴대폰 sms 본인 인증 기능 (3) | 2024.10.11 |
|---|---|
| [Django] UML Diagram 자동생성 (0) | 2024.04.05 |
| [Django] CEOS vote_project 정리 (0) | 2023.06.29 |
| AWS 배포(4) - SSH 연결 및 docker 관리 (1) | 2023.05.24 |
| AWS 배포(3) - https, 도메인 (0) | 2023.05.24 |



